|
Infopost | 2022.11.19
|
|
 |
Last time I got
Stable Diffusion's Hello World going (with some video card and Python IDE side quests).
This time: prompts and parameters.
Strength
The strength parameter is a 0.0-1.0 value that
determines how creative the model will be with the image/text inputs. Here's the above photo of Vale with a descriptive prompt demonstrating strength values from 0.1-0.9:
As the machine learning model is given more freedom to redraw the scene,
Vale winds up back on a Yamaha, but on a bike that doesn't look quite right. Of course, this is just one run at each strength, another strength 0.9 run might give you something entirely different (but derived from the input image and generally following the prompt).
Prompts
Both txt2img and img2img use textual prompts to re/create images.
Lexica.art has a wealth of examples that help provide empirical guidance on prompt writing.
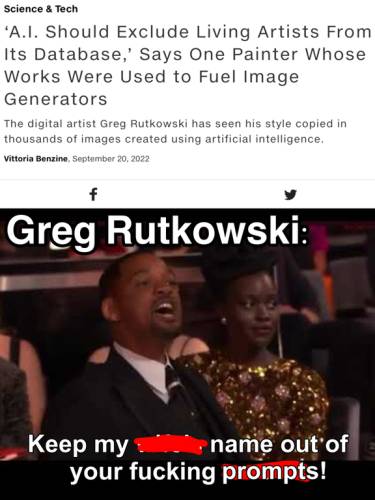
Artist
The
Andy's Blog post from last time mentioned that he saw
significantly better results when supplying one or more specific artists in the prompt. Either because his name yields good results or maybe because it's a meme,
a large chunk of Lexica uses Greg Rutkowski in its prompt. I'd never heard of Greg Rutkowski until trying out Stable Diffusion, but sure enough
he's quite prolific on Artstation which I think was one of Stable Diffusion's sources of tagged imagery.
Format
I've read a variety of things about
comma-separated tokens, natural language, and ordering by importance. The near-nondeterminism of deep learning makes it difficult to draw any conclusions on this.
The joy of AI painting using txt2img
With the basics in mind, I tried a bunch of different prompts, mostly producing 512x512 images that I've downscaled a little bit for this site. In the context of Style Transfer and Dall-e mini, the takeaway from the image dimensions is that
the output images are significantly larger than a 256x256 but still require additional work to be postcard size.
An abandoned factory
Starting simple...
ink illustration of an abandoned factory. retrofuturistic, photorealistic.
One looks like a traditional black and white photo, the other looks like architecturalish drawing. Both have signs of abandonment. One looks modern, the other looks brutalist.
A yellow starfighter
Next I juiced it up a bit, specifying subject color and a background. I pulled a random artist name from Lexica and whatever cgsociety is. And I went rectangular, probably along the wrong axis (as starfighters tend to be horizontal not that it matters in space).
python scripts/txt2img.py
--prompt "A highly detailed painting of a futuristic starfighter.
Yellow body, glowing cockpit. Concept art by ian mcque,
cgsociety. Sci-fi. Stars and nebulas can be seen in the
background."
--n_samples 8
--H 640 --W 320
Some of these
look like 70s sci-fi novel cover art. Cool.
CGI tools
Some of the prompts
specified a rendering platform (Unreal Engine, Maya, etc.), I think rendering and postprocessing tools are one of the tags in Artstation.
octane rendering of a colorful wormhole. soft lighting, cyberpunk,
hyper realistic.
It even has a watermark.
Vocabulary
Six months ago the PUBG crew
was wowed that Dall-e knew about battle royales. Stable diffusion does too:
Skaggy style
Likewise, SD knew about Claptrap and Borderlands art style. I used another random Artstation creator from Lexica.
unreal engine rendering of claptrap from borderlands in a field.
grainy, solarpunk, smooth render. in the style of andrei riabovitchev.
Looking at
Andrei's work the Borderlands elements seem to have dominated the style input.
Twist of the wrist
Trying some more subject/scene interplay:
source filmmaker cgi rendering of an aprilia motorcycle with blue accents
in a postapocalyptic waterfall. cyberpunk, photorealistic.
It doesn't look like a Prilly, but SD nailed the postapocalyptic waterfall. Other than some subtle details, the bike looks really good. Another:
cross-processed photograph of a ducati in a town square. dark, futuristic,
clean composition.
Go with what it knows
SD (as I understand it) is trained on a boatload of real images with human-applied tags. If you've seen the Silicon Valley where Erlich enlists Big Head's college class to tag datasets for him, it's unrewarding work.
The neat thing about using Artstation (and others?) as a datasource is that the imagery there is tagged and ready for deep learning consumption.
So while Stable Diffusion might have to guess what a banana with a goatee looks like,
it can recreate isomorphic things with considerably more certainty. Likewise, if every instance of something looks very different ("draw me a vehicle") an SD prompt might yield a mashup of those things. But a more refined command like "draw me a Jaguar XJ220" will give it more specific criteria to generate from.
Further, let's consider a Ferrari, here's some mild hyperbole that probably dicatates how well a deep learning algorithm can understand one:
- There are lots of photos/drawings of them.
- Exotic car photos usually have just a few canonical angles.
- They come in like three colors.
- They aren't typically modified.
- The company has a signature style that is visible in most of their vehicles of a given generation.
So 'car' is bad, 'Bugatti' is good, 'Toyota' is okay. Your mileage may vary.
Monochrome photograph of a Lamborghini parked in the rain. Contrasty.
Highly detailed but smooth.
The joy of AI repainting using img2img
Switching gears (lmao) to the other side of Stable Diffusion,
prompts are just as important to img2img.
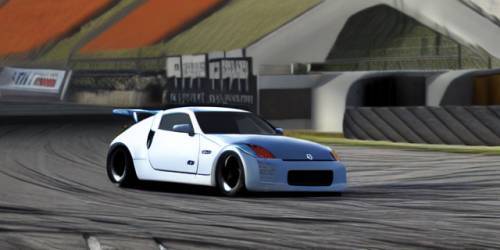
Drifter
I grabbed a photo from the archive and asked Stable Diffusion to recreate it in something contextually-similar: Gran Turismo.
Writing a specific prompt (not sure if this is good or bad) was a lot easier since I just had to describe what's in the image.
cgi rendering in the gran turismo engine. nissan 350z drifter on a
racetrack. tires smoking, front wheels at opposite lock. stickers
cover the scuffed bodywork.
It's definitely Gran Turismo-like. That last car's spoiler seems to be glitching though.
Archangel
Since Stable Diffusion knows about Borderlands, I thought I'd try a screencap of everyone's favorite Turian police sniper? Just to throw it a curveball, I asked for a plate of nachos.
detailed 35mm photograph of garrus vakarian from mass effect. standing in
front of colorful artwork, holding a plate of nachos.
Photo -> cgi worked pretty well with the 350Z,
cgi -> photo wasn't so good. 33% nacho rate though. Not bad.
AI green screen
Back to contextually-similar, recognizable things, I asked Stable Diffusion to reimagine a paintball photo as a highly specific war photograph.
world war 1 photograph of troops crossing no man's land wearing gas masks.
smoke billows in the background. mortars explode nearby.
Faces and hands
Things frequently go awry when Stable Diffusion tries to do faces and hands, with the exception of passport-headshot-style photos that are probably well-represented in its dataset. Generated words resemble text but aren't coherent (see above where Valentino Rossi is riding an "OIHNJOD").
- Photo -> CGI: good
- CGI -> photo: meh
- Photo -> painting: ???
I wanted to see how a photo would look as a painting.
digital painting of a surfer sitting in the lineup. wearing a shark tooth
necklace because he's a kook. very detailed, art by greg rutkowski.
pastel colors. green water, blue sky.
Stable Diffusion was pretty shy about redrawing the subject's face. Other things turned out rather incoherent. I said Greg Rutkowski, not
GWB.
Iterating img2img
You guessed it,
img2img outputs can be pruned and fed back into the algo with an identical or modified prompt. Here are some (not the same prompt):
A generative pipeline
Now for an end-to-end run:
txt2img followed by numerous passes of img2img with refined prompts.
cgi rendering of a gray lamborghini in the rain. contrasty, epic,
hyper realistic.
Draw me some lambos.
Oh yeah, AI can't draw wheels very well either.
Let's go with the low-angle one in the rain.
Time to fire up img2img. Monochrome is nice and all, but these cars deserve bright colors so let's change the prompt a little:
Colorful cgi rendering of a bright green Lamborghini in the rain.
Contrasty. Highly detailed but smooth.
and one of the photos looks like a fireplace. Hmmm. Maybe the one with the neat reflection. Let's keep the bright green and instead put the lambo in its natural environment: the garage. Just kidding, the track.
Colorful cgi rendering of a bright green Lamborghini at Suzuka Raceway
in Japan. Contrasty. Highly detailed but smooth.
I see some grandstands and some safety barriers. The one with the short depth of field is pretty awesome though the car's front right wheel well may have disappeared. On the plus side, the car is truly bright green with some neat orange accents on the grill.
Let's try a different color scheme and maybe see if Stable Diffusion will put a muscle car air cleaner on a Lamborghini frunk (golf clubs need high-psi ventilation too).
Colorful cgi rendering of a Lamborghini in the orange and blue Gulf Oil
racing lervery. On track at Suzuka Raceway in Japan. Hood as a large
air cleaner hood scoop for its supercharger. Contrasty. Highly detailed
but smooth.
We're still pretty green and not at all looking like a GT40 lookalike.
Either 'Gulf Oil livery' isn't well represented in the dataset or we left the strength value too low in trying to preserve our work so far. Stable Diffusion did get creative with a Bugatti-ish redesign.
But what if the car was not on a racetrack in Japan but actually in the Swiss Alps? Well then it'd probably need to be a Lamborghini trophy truck.
Colorful cgi rendering of a lifted Lamborghini trophy truck racing in the
snow in the Swiss Alps. Contrasty. Highly detailed but smooth.
We got a couple of low-poly trophy trucks, a near-redraw, and a neat version on a snowy city street.
And this is how you can meander for hours without touching a single paintbrush or OpenGL API call.
Additional checkpoints
So this
nitrosocke guy created
a checkpoint (set of trained models) using Elden Ring images. I envision this as being like
transfer learning wherein final model is a generalized network (like a trained VGG-19) that is adapted to a specific dataset.
The Elden Ring style checkpoint is cool and worth dedicating some post to, but it's even more than that. The Elden Ring outputs are really good. That is,
the images are more distinct, coherent, and stylistically-accurate than stuff generated by the base model. Of course it would make sense that a specialized network is better at its job.
There's one caveat that I'll mention after some Elden Ring txt2img:
Caveat:
Elden Ring characters often armor covering their face and hands so it sidesteps SD's weakness.
Trading Torrent out for a motorcycle
(Torrent is your horse in Elden Ring.) Back to transfer learning, since the Elden Ring checkpoint derives from a more generalized base model, it knows what a motorcycle is.
|
|
Source. Kind of like the Thomas mod for Skyrim. |
Elden Ring-Mass Effect crossover
Armor makes the jump pretty easily from sci-fi to fantasy.
Caelid Highway
There were some interesting takes on the Z-car photo, including one that had Gran Turismo in the prompt.
Paintball with scythes
The paintball image was easy for SD to redraw in Elden Ring style.
Code
The canned examples are pretty good for one-off runs, but consistency isn't great.
A successful generative process requires a lot of runs and a lot of variation. The Stable Diffusion sample scripts are small enough to modify easily, but do require some work (e.g. nested withs that have you starting lines at column 60). I made the following mods:
- Parameterized repeat runs (not using batching) as well as iterating over a full directory of inputs.
- Parameter randomization (strength, ddim, etc.).
- A prompt generator and mutator, e.g. "photo/photograph/35mm photograph of red/green/blue lambo/ferrari/citroen on a street/track/dirt road by greg rutkowski/greg rutkowski/greg rutkowski".
Will be interesting to see how the preparties/stadium walks change.
|
Infopost | 2022.11.14
|
|
 |
 |
Last post had some funny Elons. Here's how I made them. Well,
here's how a machine learning model made them with me serving as quality control.
"Hey check this out"
A few months back,
Zac linked
this blog post about
the new AI hotness, Stable Diffusion. Having recently
upped my CUDA game, I decided to give this model a try.
Environment
This part is boring but contains highly-specific troubleshooting information, for casual consumption skip down to "a photograph of an astronaut riding a horse".
Video cards don't hot swap
|
|
|
Since I had Dall-e draw a 'neural graphics card', I asked Stable Diffusion to do the same. It probably needed more guidance. |
I can't remember the last time I
upgraded a video card without refreshing the rest of the system, but here I was yanking a 1060 and replacing it with a 3080. Windows was somewhat straightforward: remove hardware, uninstall nvidia tools, put in card, install. I didn't touch cuda, cudann, etc., so there may be some follow-up if and when I do ML in Windows.
For Ubuntu I just ripped and replaced the card, then tried to apt install the updated drivers. Alas, the installer
halted on discovering that the 'nvidia-drm' kernel module was still running. The fix I found:
-- Remove nvidia-drm --
control alt f3 # Kill xwin, log in as root.
systemctl isolate multi-user.target # Remove any concurrent users.
modprobe -r nvidia-drm # Remove the nvidia-drm module.
systemctl start graphical.target # Restart xwin.
The lands between RTX and Python
There's a lot of software between nvidia drivers and a PyTorch script. On my box, all of it remained from the 1060 era, so
I wasn't sure how they'd do with their underlying software (the graphics card driver) changing.
Updating PyTorch
was previously kind of a pain, so I tried to avoid it, alas:
NVIDIA GeForce RTX 3080 Ti with CUDA capability sm_86 is not compatible
with
the current PyTorch installation. The current PyTorch install supports
CUDA
capabilities sm_37 sm_50 sm_60 sm_70. If you want to use the NVIDIA
GeForce
RTX 3080 Ti GPU with PyTorch, please check the instructions at
https://pytorch.org/get-started/locally/
I was on cuda_11.5.r11.5 and my existing Torch install was for 10.2:
In : torch.__version__
Out: '1.12.1+cu102'
In : torch.cuda.get_arch_list()
Out: ['sm_37', 'sm_50', 'sm_60', 'sm_70']
Some github bug thread mentioned that
3080s were not supported on that verison of cuda. The nvidia
Getting Started Locally link told me to run:
pip3 install torch torchvision torchaudio
--extra-index-url https://download.pytorch.org/whl/cu115
That command only successfully installed torchaudio.
So I went back through the previous steps of checking
the available wheels and pointing pip to the right one.
torch-1.12.1+cu113-cp39-cp39-win_amd64.whl
torch-1.11.0+cu115-cp310-cp310-linux_x86_64.whl <--
torch-1.11.0+cu115-cp310-cp310-win_amd64.whl
torch-1.11.0+cu115-cp37-cp37m-linux_x86_64.whl
torch-1.11.0+cu115-cp37-cp37m-win_amd64.whl
torch-1.11.0+cu115-cp38-cp38-linux_x86_64.whl
torch-1.11.0+cu115-cp38-cp38-win_amd64.whl
Basically what Getting Started Locally said, but with the specific Torch versions:
pip3 install torch==1.11.0+cu115 torchvision torchaudio
--extra-index-url https://download.pytorch.org/whl/cu115
Voila:
In : import torch
In : torch.cuda.get_arch_list()
Out: ['sm_37', 'sm_50', 'sm_60', 'sm_70', 'sm_75', 'sm_80', 'sm_86']
And just to be sure, I checked that torch and cuda both were working:
In : import torch
In : x = torch.rand(5,3)
In : print(x)
tensor([[0.2007, 0.7051, 0.0065],
[0.6201, 0.0654, 0.0358],
[0.5384, 0.0370, 0.5332],
[0.1488, 0.7525, 0.6938],
[0.1375, 0.6065, 0.1435]])
In : torch.cuda.is_available()
Out: True
Pip
There wasn't a requirements.txt that I could find, so I also needed to get:
pip3 install opencv-python
pip3 install taming-transformers
Models and checkpoints
The readme said to run
the model(?) downloader script, it took several hours. Next I needed model checkpoints, available after creating an account on Hugging Face and symlinking one of the files in the specified directory.
Quantize.py
Finally, I ran the Hello World script:
python scripts/txt2img.py
--plms
--prompt "a photograph of an astronaut riding a horse"
No astronaut, only:
ImportError: cannot import name 'VectorQuantizer2' from
'taming.modules.vqvae.quantize' (~/.local/lib/python3.10/site-packages/
taming/
modules/vqvae/quantize.py)
From
this,
something in the Stable Diffusion stack uses a no-longer-supported library, but you can download
the right one and update the various Python packages manually.
Side quest: Spyder
I haven't done a ton of Python at home or work until recently. IDLE and emacs aren't super great for it, so
in searching for a proper IDE I came upon Spyder. It seems to hit the sweet spot of not being too invasive (Eclipse) while being helpful (autocomplete and robust syntax assistance). It's "a Python IDE for scientists" so -1 for being pretentious.
Sure, let's do more troubleshooting
Alas,
the Spyder version in apt is apparently really old and chokes on a recent installation of Qt/QtPy. Since there's no standalone Linux installer, the solutions are:
- Use Conda. No thank you.
- Roll back Qt and/or use Docker. Nahhhhh.
I elected to go with option three. The exception pointed me to Spyder's install.py where
the incompatible lines of code all seemed to be about scaling raster images. I don't expect to heavily use raster images in a Python IDE and probably have the screen real estate to accommodate full size ones, so I commented out these lines. I expected another wave of Qt exceptions when I fired 'er back up, but everything worked.
12gb is not enough, but it is enough
I tried the
txt2img.py script that's basically Stable Diffusion's Hello World:
RuntimeError: CUDA out of memory. Tried to allocate 1.50 GiB (GPU 0; 11.77
GiB total capacity; 8.62 GiB already allocated; 654.50 MiB free; 8.74 GiB
reserved in total by PyTorch) If reserved memory is >> allocated memory
try setting max_split_size_mb to avoid fragmentation. See documentation
for Memory Management and PYTORCH_CUDA_ALLOC_CONF
Was tripling my video memory not enough? The messages is a bit unclear, as was repeated on the torch forums:
 abhinavdhere
abhinavdhere |
I got "RuntimeError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 10.76 GiB total capacity; 9.76 GiB already allocated; 21.12 MiB free; 9.88 GiB reserved in total by PyTorch)"
I know that my GPU has a total memory of at least 10.76 GB, yet PyTorch is only reserving 9.88 GB.
In another instance, I got a CUDA out of memory error in middle of an epoch and it said "5.50 GiB reserved in total by PyTorch"
Why is it not making use of the available memory? How do I change this amount of memory reserved?
|
Running nvidia-smi told me that steady state gpu memory used was 340MiB / 12288MiB, so running this without a GUI wasn't going to make much difference.
|
Umais |
I have the exact same question. I can not seem to locate any documentation on how pytorch reserves memory and the general information regarding memory allocation seems pretty scant.
I'm also experiencing Cuda Out of Memory errors when only half my GPU memory is being utilised ("reserved").
|
Others seemed to experience the same thing (in 2020) and I'm not the only one who sees ambiguity in that memory math.
|
ptrblck |
Yes, [multiple processes having their own copy of the model] makes sense and indeed an unexpectedly large batch in one process might create this OOM issue. You could try to reduce the number of workers or somehow guard against these large batches and maybe process them sequentially?
|
Ptrblck was addressing an issue with parallel processes sharing the GPU, but this was conceptually the same problem as mine.
When I dialed down the txt2img batch size or output dimensions, I stopped hitting the OOM exception. Deep learning model sizes explode when you increase image height and width; all of those highly-connected nodes must connect to exponentially more peers. In my limited experience, batch size (number of images you feed in at a time) only scales memory usage by a multiple of the input/output dimensions. Maybe Stable Diffusion handles batching differently. According to
this thread there may be some platform-layer memory management issues that could be resolved with additional updating.
An aside
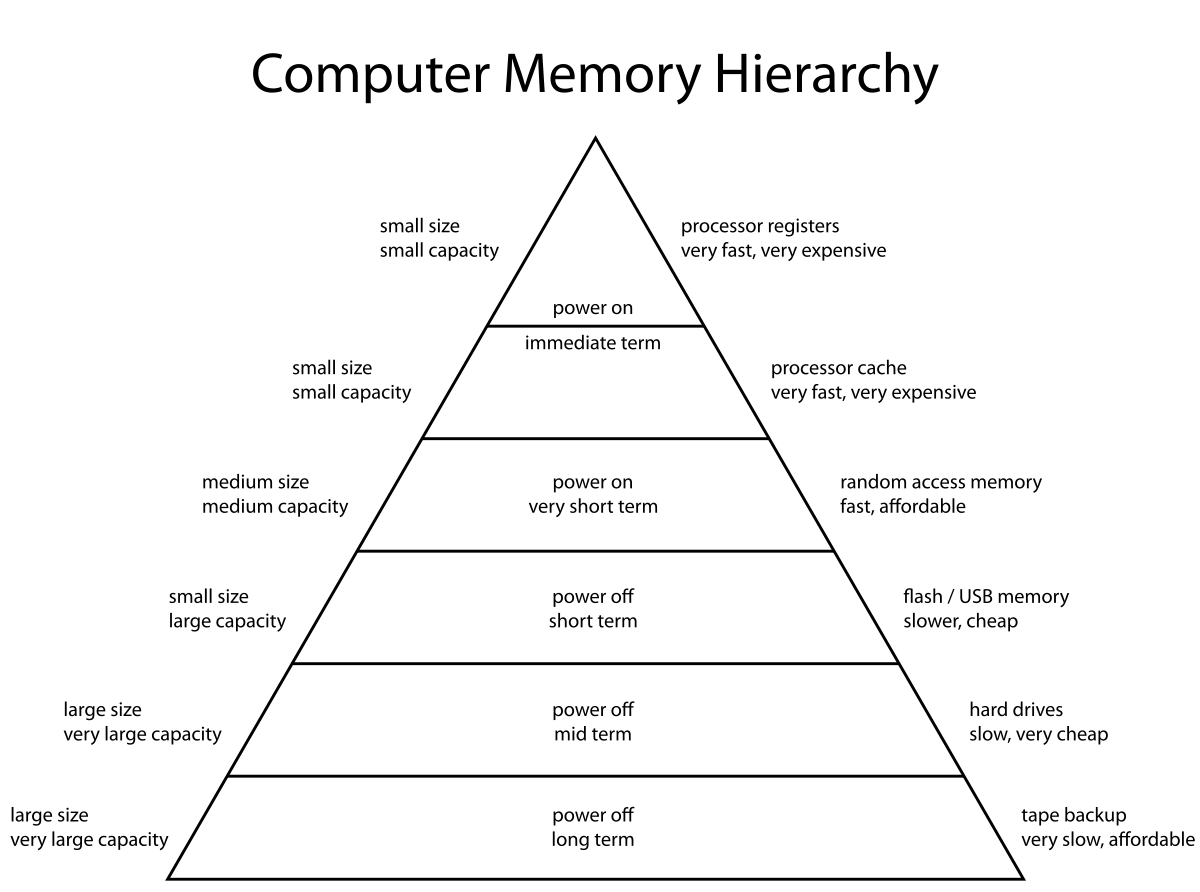
It's perhaps worth noting that this exposes a major shortcoming of ML platforms, they don't leverage the lower half of the memory pyramid.
Hardware-accelerated machine learning (at the consumer level) runs everything out of GPU memory,
this sets a fairly rigid boundary on problem size. If these platforms could wisely page out to computer main memory and virtual memory, that 12gb or even 48gb ceiling wouldn't be so hard.
It would be a little less challenging to support parallelism - connect identical 4090s and treat them a two processing cores with a single blob of mutually-accessible memory (mildly impacted by bus throughput). From the desktop machine learning enthusiast perspective, it means I could spend a paltry $1000 to double my model capacity. Alas, this
doesn't seem to be supported.
And so the only way to throw money at the problem is to
move from a $1000 gamer graphics card to a $10,000 48GB data center card. Or, of course, buy time at one such data center.
Models like Dall-e and Stable Diffusion have text interpretation components, graphics inference components, and generative components. I haven't peeled back the layers to know how separable these models are, but another theoretical solution is to partition the models under the hood. This requires that each step of the process be separable and would incur a performance hit of unloading/loading between stages of the pipeline.
Hello World
After all that I was able to run the Hello World script from
the docs:
python scripts/txt2img.py --plms
--prompt "a photograph of an astronaut riding a horse"
Well, deep learning is very sensitive to parameters so let's count successful execution as a win and try the other application of Stable Diffusion, img2img.
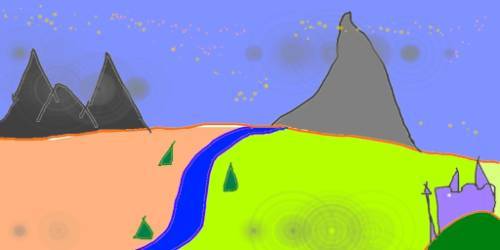
The input is an mspaint-tier drawing of a mountain and river.
Combining that input image with a text prompt should produce something like this:
python scripts/img2img.py '
--prompt "A fantasy landscape, trending on artstation"
--init-img input.png
--strength 0.8
My results weren't quite as refined, but certainly in the ballpark:
Variations and dimensions
txt2img
I ran the equestrinaut example with the default batch size (6) and had to dial down the output dimensions to not OOM my GPU.
Spamming nvidia-smi, I saw a peak usage of about 9gb:
python scripts/txt2img.py
--prompt "a photograph of an astronaut riding a horse"
--plms
--H 256
--W 256
+--------------------------------------------------------------------------
-+
| Processes:
|
| GPU GI CI PID Type Process name GPU
Memory |
| ID ID Usage
|
|==========================================================================
=|
| 0 N/A N/A 2106 G xwin
160MiB |
| 0 N/A N/A 2336 G xwin
36MiB |
| 0 N/A N/A 4618 G browser
142MiB |
| 0 N/A N/A 9537 C python
8849MiB |
+--------------------------------------------------------------------------
-+
I tried 512x448 and 512x324, both exceeded my 12gb video memory. I should note that these runs were done before the batch size fix discussed above (for topicality), these dimensions would probably work with a small batch.
I switched up the prompt and found that 448x256 worked:
python scripts/txt2img.py
--prompt "a computer rendering of a sportbike motorcycle"
--plms
--H 256
--W 448
Rigid airships
looked cool with Dall-e, so let's try:
python scripts/txt2img.py
--prompt "a zeppelin crossing the desert in the style of ralph
steadman"
--plms
--H 256
--W 512
+--------------------------------------------------------------------------
-+
| Processes:
|
| GPU GI CI PID Type Process name GPU
Memory |
| ID ID Usage
|
|==========================================================================
=|
| ...
|
| 0 N/A N/A 5211 C python
9743MiB |
+--------------------------------------------------------------------------
-+
img2img
For img2img I tried to channel both Andy's Seattle and the serene landscape of the github example. A zeppelin floats above Florence. And let's do an oil painting rather than a photo or cgi render.
python scripts/img2img.py
--n_samples 1
--n_iter 1
--prompt "Oil painting of a zeppelin over Florence."
--ddim_steps 50
--scale 7
--strength 0.8
--init-img florence.png
+--------------------------------------------------------------------------
-+
| Processes:
|
| GPU GI CI PID Type Process name GPU
Memory |
| ID ID Usage
|
|==========================================================================
=|
| ...
|
| 0 N/A N/A 8005 C python
7709MiB |
+--------------------------------------------------------------------------
-+
My 3080 easily accommodated a 448x336 image, probably because I set the samples/iterations to one.
The first pass gave me a simple-but-coherent take on my input image as well as something, well, abstract.
Using the successful one for a second pass,
Stable Diffusion churned out a more colorful redraw as well as something significantly different. Alas, my zeppelin had turned into clouds.
A third pass on the more detailed image brought out some of the details:
Not quite Andy's postapocalypse/preinvasion Seattle, but it's a pretty good Hello World.
The lack of detail could be the oil painting directive, an ambiguous text prompt, or something else.
Hello World++
|
|
From the Stable Diffusion sub that also has this instructional. |
Style Transfer was a neat image-to-image application but compute-intensive and noisy.
Dall-e Mini introduced (me to) a generative model using text inputs.
Stable Diffusion can do all of these. For serious digital artists, it can be part of a traditional Photoshop/Illustrator-heavy pipeline, e.g. the image above. For the more casual user, it can
'imagine' things from a text prompt or stylize a photo/drawing:
- Big video card upgrade, now I can run Stable Diffusion.
- Elon is now Twitter's founder.
- Friendsgiving happened in Vegas.
- We replaced the termite farm.
- I tried to download some music.
1060->3080
I picked up a 3080 Ti from some decent ebay seller after being ghosted by an illegitimate ebay seller. I was looking to catch the price downswing from:
- The 4090 release.
- The crypto crash/Ethereum moving from proof of work.
I normally don't get the tippy top (e.g. a 1060 in the 1080 era) but
might have considered a 4080. Nvidia only releasing the 4090 this year made my mind up.
With more than 4GB of video memory I can do machine learning. Games probably look good, but the lolbaters squad has been on hiatus.
Twit
Revisiting the conspiracypost
Last time I indulged
some wild speculation about the Musk-Twitter situation. I wasn't the only one,
Rob promptly linked this Matt Levine post from October 24:
|
Matt Levine |
"The most entertaining outcome is the most likely," Elon Musk once tweeted, as far as I can tell not about a particular event but as a general life philosophy. In that spirit, let me put out into the world that the most entertaining outcome of Musk's deal to buy Twitter Inc. is obviously:
- Having agreed to close the deal by 5 p.m. this Friday, Musk in fact closes the deal by 5 p.m. this Friday, paying $54.20 per share to all of Twitter's shareholders and taking over the company.
- At 5:01, Joe Biden calls Musk and says "I am sorry, but we have decided that it is a national security risk for you to own Twitter, you will have to divest it immediately, this is an unreviewable and final order."
- Musk has to sell the company by noon on Monday, which he does at a fire-sale price to
its previous public shareholders? His lenders? Jeff Bezos? Mark Zuckerberg? Kanye West? Jason Calacaniss "randos"? Lots of good options here.
- He buys it for $54.20 per share this week and sells it for like $15 per share next week, losing tens of billions of dollars.
- Probably he has a really intense weekend of messing around with Twitter before letting it go? Again, many opportunities for antics.
|
It's humor, but probably worth noting that
the scenario where Elon closes the deal and then is told to sell it off doesn't make sense. At least, in my limited CFIUS experience, the transaction is simply blocked rather than unwound in some convoluted way. But what the above scenario lacks in accuracy it makes up for in entertainingness; imagine what Kanye would do with
two free speech platforms?
|
Matt Levine |
Biden administration officials are discussing whether the US should subject some of Elon Musk's ventures to national security reviews, including the deal for Twitter Inc. and SpaceX's Starlink satellite network, according to people familiar with the matter. ...
US officials have grown uncomfortable over Musk's recent threat to stop supplying the Starlink satellite service to Ukraine -- he said it had cost him $80 million so far -- and what they see as his increasingly Russia-friendly stance following a series of tweets that outlined peace proposals favorable to President Vladimir Putin. They are also concerned by his plans to buy Twitter with a group of foreign investors.
|
Also had that on my bingo card.
|
Matt Levine |
Musk is a US citizen, so he is probably not subject to CFIUS review, and kicking out his minority co-investors like Prince Alwaleed bin Talal or Binance would not derail the deal. I do not think theres much of a chance that any US government review will actually block the deal this week, or unwind it in the future.
|
The whole point is that Twitter is subject to CFIUS review because Elon and Binance are foreign entities.
You were supposed to be the chosen one
I should say that while I am not a Twitter user,
it was the social media platform I would pull out of a burning building. Tweets are nicely-packaged pieces of information that are super-portable (i.e. prime for reposting in text or image form). While a hundred and whatever characters is no substitute for complete information, users have learned to best wield the capabilities of the platform. Importantly,
tweets have provided some excellent "this u" stories over the years.
The obvious drawback to Twitter is that it doesn't easily support the long-form discussion - that's fine as long as it isn't meant to replace long-form discussion. It's somewhat annoying that lurkers have limited visibility of a Twitter stream, though this is considerably better than the Facebook/Instagram walled garden.
So I secretly hope that Elon doesn't destroy Twitter.
The story that keeps giving
I'm not going to pretend to know what's true and what's sensationalized, but
the acquisition has given us some gold:
- Apparently a lot of Elon's texts were disclosed in the Twitter-Musk lawsuit. I didn't read the source material, but the tldr indicated that the texts make him look somewhat amateurish. Like he'd step into the role and try to make the company worth 40B by charging their content creators to use the service. Also he apparently has some dedicated VC fanboys.
- Another rumor: Twitter employees were asked to print their code contributions from the last year, ostensibly because layoffs would be based on code volume. I want to believe Elon (and his Tesla mercenaries) are a little smarter than that and that this was simply a loyalty test.
- Elon feuded with Stephen King over a monthly fee for blue checks.
- Twitter employees were told to work nights and weekends to get the blue check payment system going.
- After declaring comedy's return to his free speech platform, Elon has been purging blue checks who violate the sanctity of their verification by changing their name to Elon Musk and claiming to, for example, drink their own piss every morning. Is it parody? Is it misinformation? It's hilarious.
A lot of this seems to hint at a loyalty purge. As many have pointed out, voluntary layoffs helps with downsizing expenses. And, well,
Elon's neither a fan of WFH or California, so he might be requiring a mass relocation.
This is all funny, but I should say that Tesla and SpaceX seem to have been run pretty well (though long hours are on-brand). Was Elon just the front man for the executive staff at these companies? Or
is Twitter not quite the clown show it appears?
Gallery
I don't want to post more Elon faces, but
Stable Diffusion did such a good job with the memes that I have to post em. We're sadly missing a Boat Elon (best Elon).
Holidays
It's election day.
Last week was Halloween.
The weekend before was Friendsgiving.
Wood->vinyl
We finally had the deteriorating cedar fence replaced with vinyl.
The record store
Downloading some fresh music was in the backlog until this past weekend. I have been meaning to get the recent Tool album since first hearing it
live.
Mark had pointed me to a neat prog/instrumental group (above) and I ran across
some Reddit post in defense of the last decade of hip hop (which has been somewhat unimpressive imho). I balked at seeing Kanye and RtJ (sorry, hipsters) on the list, but DOOM and Black Thought brought me back. And I guess if Mr. Hip Hop is Dead made the list, it can't all be 16 bars of the same sentence repeated over a catchy hook.
Here are the last two years, I put the rest of the list at the bottom:
|
Some Redditor |
[2021:]
Tyler, the Creator - CALL ME IF YOU GET LOST
Backxwash - I LIE HERE BURIED WITH MY RINGS AND MY DRESSES
Vince Staples - Vince Staples
J. Cole - The Off-Season
Little Simz - Sometimes I Might Be Introverted
[2022:]
JID - The Forever Story
Boldy James & Real Bad Man - Killing Nothing
Pusha T - It's Almost Dry
Black Thought & Danger Mouse - Cheat Codes
Denzel Curry - Melt My Eyez, See Your Future
|
Previewing and downloading the music wasn't as simple as I remembered.
Amazon
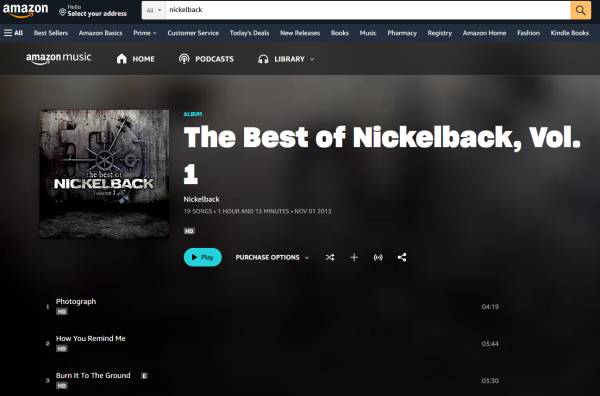
I actually first got into Amazon because (back in the 2000s) they had a very simple mp3 store: pay $10 for an album or $1 for a track (mostly), download the mp3 from the browser.
No itunes, no cloud, no DRM player. You could go to a digital album and preview each track, you know, so you don't spend a buck buying a skit track or le artistic five minutes of silence.
|
|
|
They each have a play button. |
Fast-forward to today, I was disappointed (but not surprised) to click on the Digital Music section of the site and find that
everything pushed me to AmazonMusic. The AmazonMusic interface, depicted above, is pure trash:
- Selecting a track from the album takes you to a player where you can only navigate forward and back (or back to the album).
- Without Prime, you get commercials or something after every couple songs. And you can't skip forward and backward. So it's a streaming platform that someone decided would be a great storefront. These are very different use cases.
- It was buggy. The player just went catatonic due to some combination of garbage coding, me not having Prime, and my Javascript blocker (that I was pretty liberal with turning on perms).
This led me to just about ragequit. Buying tracks and albums was easy enough, but
previewing the content became akin to listening to the radio.
But
the old store still kind of exists, though clicking anything resembling "mp3" takes you to the black hole that is their terrible Wannabe Spotify.
Helping:
|
|
|
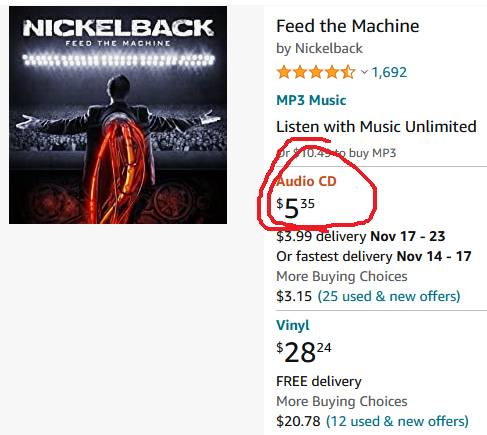
You want to get to the band keyword, though it is not a hyperlink in the results screen. So click "Audio CD" or "Vinyl". |
|
|
|
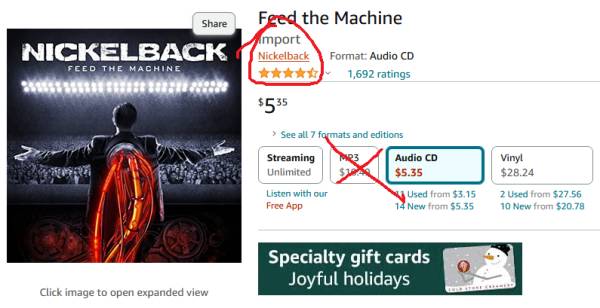
"MP3" will take you to the stupid player. Now the artist is a hyperlink. Click this. |
|
|
|
"Digital music" reveals the old-style sample page. For now. |
Anyway, Cheat Codes is great.
The full recommendation list
Let me know if any of it is worthwhile.
|
Some Redditor |
[2010:]
Kanye West - My Beautiful Dark Twisted Fantasy
The Roots - How I Got Over
Kid Cudi - Man On The Moon II: The Legend Of Mr. Rager
Waka Flocka Flame - Flockavelli
Nas & Damien Marley Distant Relatives
[2011:]
Danny Brown - XXX
Shabazz Palaces - Black Up
9th Wonder The Wonder Years
Kanye West & Jay-Z - Watch the Throne
Curren$y & The Alchemist - Covert Coup
[2012:]
Killer Mike - R.A.P. Music
Joey Bada$$ - 1999
JJ Doom - Key to the Kuffs
Ab-Soul - Control System
Death Grips - The Money Store
[2013:]
Earl Sweatshirt - Doris
Quasimoto - Yessir Whatever
A$AP Rocky - Long.Live.A$AP
Eminem - The Marshall Mather LP2
Black Milk - No Poison No Paradise
[2014:]
Schoolboy Q - Oxymoron
Busdriver - Perfect Hair
Mick Jenkins - The Waters
Mac Miller - Faces
Step Brothers - Lord Steppington
[2015:]
Kendrick Lamar - To Pimp a Butterfly
Drake - If You're Reading This It's Too Late
Travis Scott - Rodeo
Logic - The Incredible True Story
Donnie Trumpet & The Social Experiment - Surf
[2016:]
Chance The Rapper - Coloring Book
Run the Jewels - Run the Jewels 3
Aesop Rock - The Impossible Kid
A Tribe Called Quest - We got it from Here... Thank You 4 Your service
Isaiah Rashad - The Sun's Tirade
[2017:]
Jay-Z - 4:44
Open Mike Eagle - Brick Body Kids Still Daydream
Big K.R.I.T. - 4eva Is a Mighty Long Time
Migos - Culture
Jonwayne - Rap Album Two
[2018:]
Kids See Ghosts - KIDS SEE GHOSTS
Tierra Whack - Whack World
CZARFACE & MF DOOM - Czarface Meets Metal Face
Noname - Room 25
Black Thought - Streams of Thought, Vol. 1
[2019:]
JPEGMAFIA - All My Heroes Are Cornballs
Freddie Gibbs & Madlib - Bandana
Rapsody - Eve
Dreamville - Revenge of the Dreamers III
Sampa The Great - The Return
[2020:]
Benny The Butcher - Burden of Proof
Nas - King's Disease
Ka - Decedents of Cain
Jeezy - The Recession ll
21 Savage & Metro Boomin - Savage Mode II
[2021:]
Tyler, the Creator - CALL ME IF YOU GET LOST
Backxwash - I LIE HERE BURIED WITH MY RINGS AND MY DRESSES
Vince Staples - Vince Staples
J. Cole - The Off-Season
Little Simz - Sometimes I Might Be Introverted
[2022:]
JID - The Forever Story
Boldy James & Real Bad Man - Killing Nothing
Pusha T - It's Almost Dry
Black Thought & Danger Mouse - Cheat Codes
Denzel Curry - Melt My Eyez, See Your Future
|































































































































































































![[+]](https://www.chrisritchie.org/kilroy/archive/2022/10/oktoberfest.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/07/warrior.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2022/05/carousel_ride.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2019/01/viscera_cleanup_mop.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2022/09/across_the_obelisk_martyrdom.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/02/far_cry_view_00.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2022/05/elden_ring_jarburg.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2017/05/dying_light_stadium.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2022/05/elden_ring_flamethrower.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2016/04/division_helo_00.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2022/06/leopard.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/11/deezer.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2022/05/elden_ring_erdtree_avatar.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2020/09/da_bears.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}