|
|
|
What Stable Diffusion thinks 'Year 2023' looks like. |
Here's what got clicks in 2023.
Images
Posts
1.ODST
ODST is Halo's darker, more stylistic installment. It plays about the same, though they tried to do maps and objectives. Since each of these campaigns is maybe 8-12 hours, they are thoroughly enjoyable even without major gameplay additions.
[Full post]
2.Charging on January 6th
Couldn't resist with that title. Photo conditions today were a bit challenging. Even at low tide, the break was pretty far out. The inside waves were also tall and mushy enough to occlude a lot of the action and throw mist on the rest. I stopped over at Scripps after Black's but the wind had killed it. I cropped the bottom of most of these.
[Full post]
3.Michael Bay area
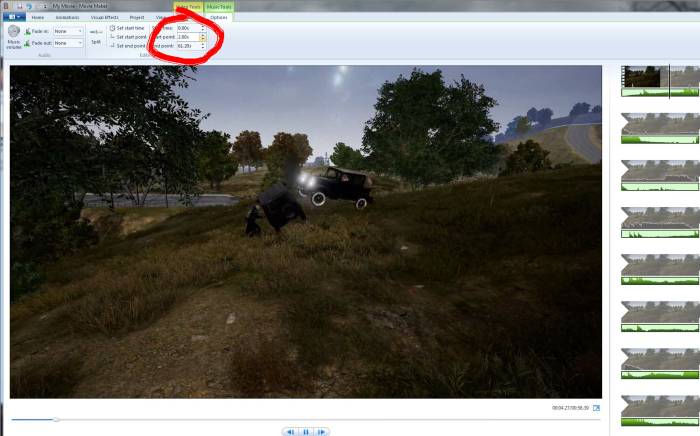
The PUBG video editor: basics and best practices.
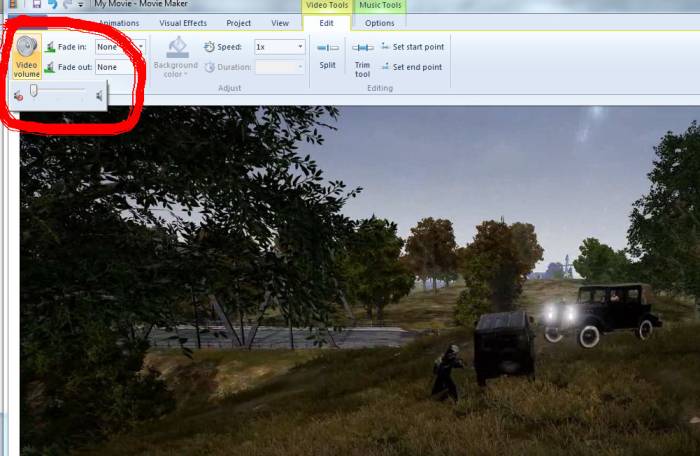
I have a sound card. I guess that's not normal anymore, but out of habit I bought one for my last pc build. I'm happy with it. It has a leet red led and also 'Scout Mode' which (I think) is just an eq setting to amplify footsteps. While I like hearing enemies like the pros, I suspect having a sound card is the source of audio being all screwed up when I export a replay.
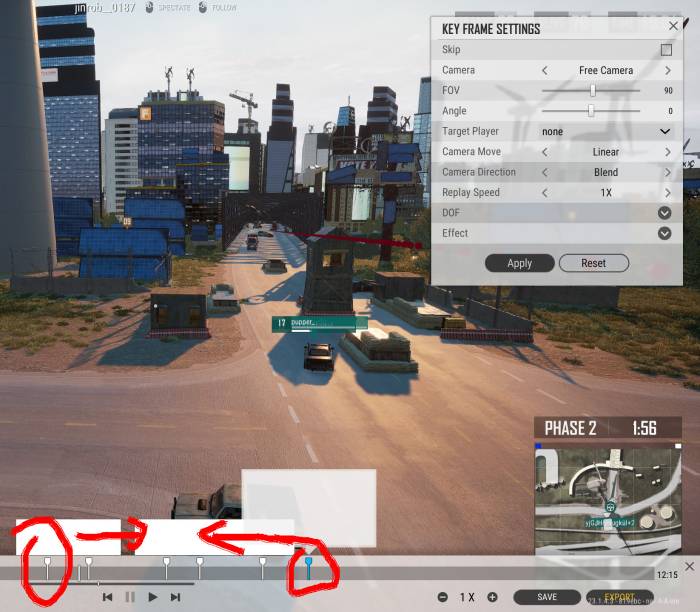
The basics: the replay editor is under 'Career'. The default mode is view-only, 'J' key gives you a timeline to hop around. If you press 'Edit' it will bring up camera controls and the like.
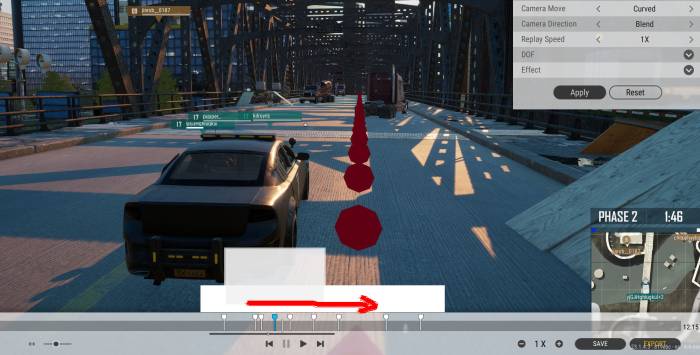
Blue circle:
The red circle highlights a slider that controls timeline zoom. For our purposes, find your battle with the timeline zoomed out, then drag this slider to the right (I mostly have it at 3/4ish) so you can navigate your battle's timeline with higher precision.
[Full post]
4.Graphic art
Look, I haven't followed baseball since the strike and I hate all those sites that steal content from the Jalponiks and Reddits of the world. But here is some baseball content stolen from Reddit cause, like, it was funny and I learned cool A's facts.
Also, funny comments deserve recognition, looking at you /u/Ted_Dongelman. I just wish the /r/baseball crowd had set up their avatars so the quotes below didn't look so lifeless. (I re-scrape every time I generate the page, so maybe in the future they will populate).
Sure, they aren't the most bearlike bears, but they strangely seem to capture the national zeitgeist:
I'm not going to post the cropped Braves logo, it's plenty visible at the top of this post. Instead, here's the NFL version.
Before italics and boldface were a thing, people used quotation marks for emphasis. Or something, all I know is that it's hilarious that they put quotes around "The Pirates".
[Full post]
5.Up the coast
A few pics from holiday travel.
Left to right:
Christmas was pleasant. Dani loved her magnetic vegetable cutting board. I loved my white elephant National Lampoon gift box. There were dogs and bubbles and a few more rounds of Charterstone.
We enjoyed the cold weather, the redwoods, and the cider in Sebastopol's new(-ish?) town center.
Flying to/from STS was pretty easy.
The same was not true for people on Southwest.
(Via text)
[Full post]
6.Halo
After blazing through The Ascent (review forthcoming), me and J consulted the list and decided on an epic Halo playthrough. It didn't go so well.
Though Reach is a prequel, we opted to run the games in release order. After realizing that I needed to download Halo 1 from within the collection UI (rather than Steam), we hopped aboard the Pillar of Autumn.
We were immediately slapped in the face - not by elites with laser swords but rather by 3-20 fps gameplay. Like what? It's an early-2000s game running on modern hardware. The atrocious framerates were accompanied by frequent reconnect prompts and eventually a crash on the host (Steamdeck) side.
I gently suggested we have the gaming rig on ethernet do the hosting (though he has fiber), but he couldn't connect to the game session. A little bit of searching yielded this:
[Full post]
7.The humans are dead
I was at the grocery store the other day getting squeezies and more squeezies. At the checkout I inserted my card to pay and, as usual, the screen flashed some messages like "Insert your card", "Keep your card inserted", "Please don't remove card", "Okay you can remove it now".
There was a time when I'd see "Keep your card inserted" flash over to some other message and pull my card out, assuming the thing had processed. What else would the next message be for? Oh yes, to tell me to leave my card in the reader but using different words. That's always miserable because you need to have the cashier invalidate the transaction and do the whole thing over again.
Thank you, that's all for tonight, I'll be here all week.
[Full post]
|
Infopost | 2023.12.30
|
|
 |
 |
|
|
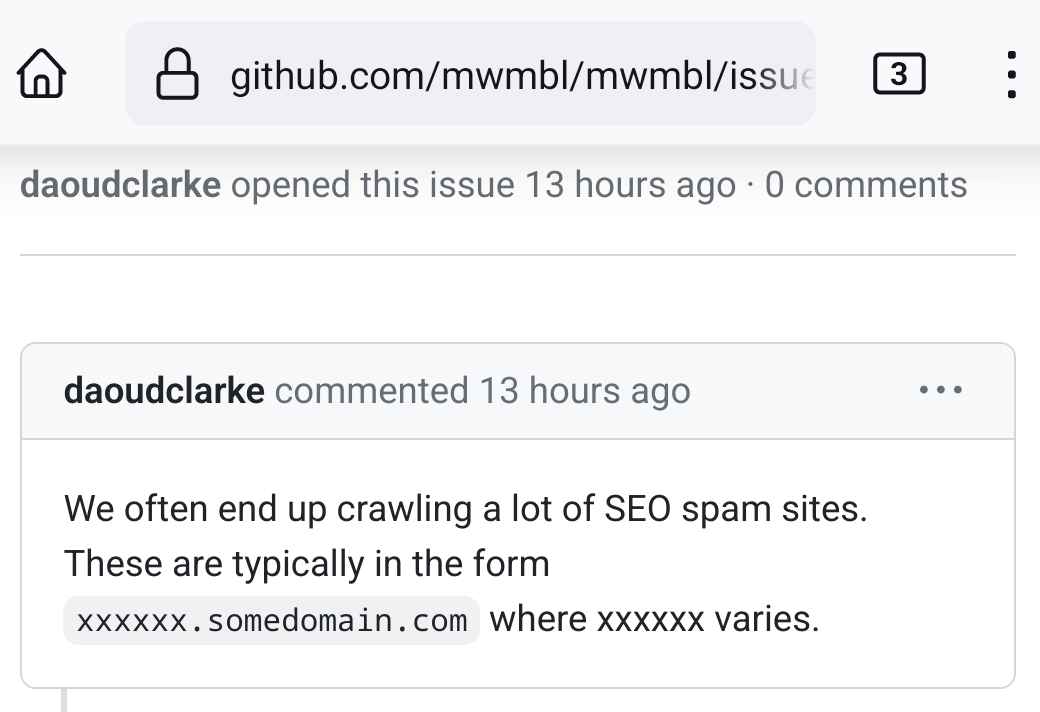
Source. I've been using galaxy maps as proxies for the internet, Rob's forthcoming guest post will explain why. |
A few months back I @ed the void with
this request for
the ability to interconnect my site with similar, noncommercial content. It was an iteration on the 'Related' section of many websites and the oldweb concepts of links pages and blogrolls. With
Twitter and
Reddit imploding and
Google being beaten by
SEO and
AI, it seemed
we needed a better means for authentic information discovery on the internet.
Well I did (a quick and dirty prototype of) it,
I fixed the internet (for my own site).
This post is mostly about the design and coding experience. If that's too dry, here are
a couple of examples of posts with relevant external links found by the crawler/recommender:
- There are a couple of posts covering alternate views of the 2003 Cedar Fire.
- My Shasta photo log links to a pair of similar experiences and a post about Kyrgyzstan since, I guess, I haven't yet discovered many casual mountaineering blogs.
- My ER-all-nighter doomscroll session during the Wagnerkrieg has some neat articles about Pringles and Russian armor woes.
Note that each of these will likely be replaced with other - presumably better - links in the future.
Seed pages and crawl queue
The internet is a pretty big place and I'm looking to connect a thin sliver of it, so having a well-managed crawl queue seemed important.
I started with RSS/Atom/Feed files - xml published by bloggers providing an inventory of their writing. This gave me a starting point of (mostly) personal web links from people looking for visibility. XML feed are, by design, easy to parse - particularly when you only care about title, description, and url. There were some adversarial feeds where, for instance Wordpress put span tags around every word. Most of this is documented
in this post.
My harsh generalization about lists of rss feeds is that
they're all written by web coders publishing recipes as a resume builder. Javascript-enjoyers and blogs go together like moths and flame or bacon and chili powder. So most of my early results were repetitive, dry, and not (what would consider) interesting subjects like wheelies and 0DTEs and object oriented code. XML feeds are considerably more pure than wild hrefs but
I quickly decided to add discovered links to my queue. My hope was that all these web coding Melvins would link to Chad friends with more content variety like fantasy football and scuba and board games. Inevitably they'd also link to Git repos and documentation pages and Stack Overflow, so these efforts to improve variety would present an snr issue. But that would be a problem I could defer until I wrote the crawler.
The crawler
The post crawler was fairly straightforward and in my wheelhouse from a previous life:
pop a url from the queue, check its robots, read the fields of interest, ensure I didn't hit the same page twice (unless re-crawl == 1). But what were the "fields of interest"? This depended on my approach for measuring similarity/producing recommendations. So we'll have to do a little (ugh, process)
preliminary design.
Similarity measurement baseline
My
internal recommendation engine ("see other posts from my site") uses this:
intersection(trigrams_a, trigrams_b)
------------------------------------------ (divided by)
(size(trigrams_a) + size(trigrams_b)) / 2
It's quick, it's straightforward, it measures terminology overlap and normalized to devalue lengthy posts. It works well for the controlled environment of my own site. But
the greater internet has all sorts of adversarial cases, purposeful and otherwise.
Going with what you know
Rob wrote some early prototypes using scikit-ish Github projects. More recently he looked at BERT and other awesome vectorization/transformation approaches. I'll defer to his eventual guestpost on the matter but, suffice it to say,
I went with a very modest recommendation engine for my first iteration. I did add
a single layer of complexity to my tried-and-true trigram implementation: emphasis words. These could be pulled from descriptions, keywords, and headers to accomplish what
tags do, but in a more generic (but less precise) way.
Preliminary design complete:
my crawler just needs trigrams from the post's plaintext and emphasis items.
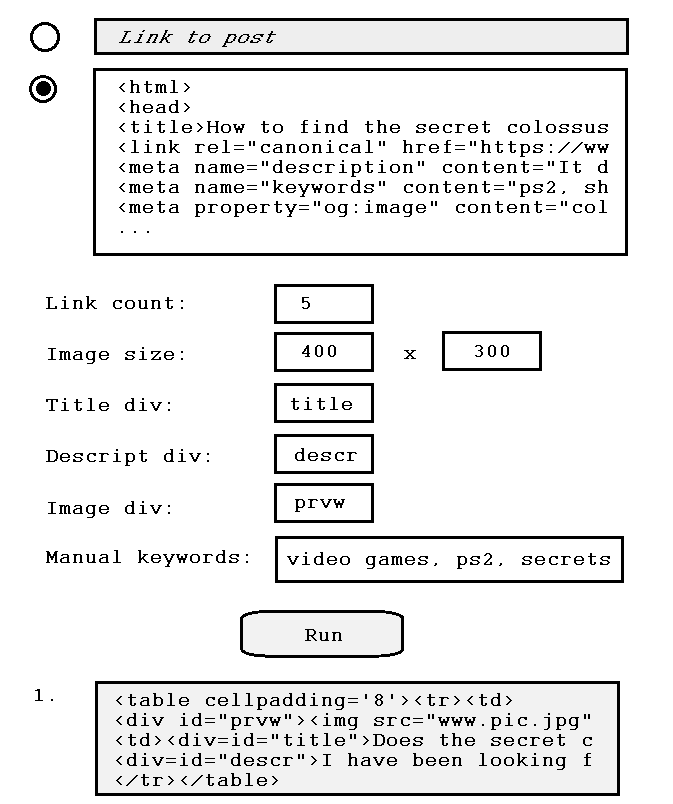
Post ingestor
Storing the post trigrams would paint me into a bit of a corner: if I wanted to come back to do tetragrams or locality sensitive hashing I'd have to re-scrape the page. So I decided to
store the post text itself and a list of emphasis terms. I could create an auxilliary trigram file and/or recreate the trigrams during comparison. But since I didn't need any html stuff, I could just have JSoup spit out the post text and slim the stored pages down considerably. More importantly, I couldn't see a scenario where I'd
want the markup except the for the probably-intractable objective of sorting the good text (post contents) from the bad (navigation, header/footer).
Since the (current) end goal of the recommender is a link preview, my ingestor also need to
parse the title, description, preview image, and canonical url from the html.
Scaling
Does this scale? The internet is big, even the non-commercial fringe is a lot to crawl and store. What's more, producing recommendations (at this stage) requires iterating over every indexed page for comparison. So while I was aiming for a minimum viable product,
I didn't want to blow up my hard drive or make a recommendation run take a long time.
So 10,000 files is a modest 100MB. That's easy to store and reasonably quick to iterate over. If this little experiment ever graduates to something more substantive, the only scaling issue is the O(N) recommendation process.
Recommender implementation v1.0
With the queue, crawler, and ingestor in place, it was time to flesh out the recommender/similarity measurement.
Trigrams and stopgrams
Since trigrams worked well for internal recommendations, I used them here. Digrams aren't enough, tetragrams are way too much. Probably. I discussed n-grams in
this post but the tldr is that n-grams are a set of each word, word pair, word triplet, and so forth. E.g. "quick brown fox" -> ["quick", "brown", "fox", "quick brown", "brown fox", "quick brown fox"]. And they're important in this application: "language" is fairly unspecific but "programming language" or "romantic language" or "gen-z language" carries a lot more meaning. I also found that proper nouns are extremely useful for associating web pages and typically require at least a digram: "Taylor Swift", "Supreme Court", "X formerly known as Twitter".
Here's an example dump of trigram intersection between a recent post and a fairly similar page from the webby web:
the site | deploy | site and | don't get | working | css | javascript |
generators | markdown | tedious | placing | compile | tech | for all |
concept | manage | the internet | tips | twitter | especially when |
comments | clean | dev | transition | static | markdown and |
static site | articles | run the | templates | websites | host |
stay | wordpress | internet | enjoy | writing | html | insights |
website | generated | them with | number | similar | city | make the |
the author | you should | features | site generators | talking about |
web | generator | user | search | seo | language | where static |
using this | publish | posts | static site generators | code | chance |
ssg | reddit | the wordpress | life | cases | templating | minimum |
create | files | netlify
This was some early data, the trigrams contain obvious stopgrams (stopword: a common word with little standalone meaning) like "don't get", "clean", and "number". These words could equally appear in a board game review or a post about a trip to Oregon. "Static site generator", "use case", and "css", on the other hand, strongly suggest the content of the text. Others, like "the wordpress" and "markdown and" don't gain much from the digram but serve to double the weight of the key word (for better or worse).
The usefulness of these tokens gets a little dicier with terms like "templating" and "static". They exist in non-programming contexts but aren't especially common. There's probably some neat Bayesian approach to be tried here (@backlog).
Stopgram efficacy
I quickly learned that
stopwords/stopgrams are very important in this approach. If Post A and Post B both talk about "Jerome Powell" and "quantitative tightening", it's very destructive to have that match be drowned out because Post A and Post C both contain the phrases, "you know what", "amirite guys", and "bananas". So my stopgram set grew with every comparison run and currently weighs in at 4,500 terms.
Despite all of this language-adjacent coding, I didn't sign up to ponder the intricacies of the English language and yet I found some things to noodle upon. In this case: that you can't just tensify every verb and plural every noun and verb every noun, every stopgram demands consideration. "World" doesn't say much about a particular post but "worlds" is a strong push in the direction of fiction/fantasy/sci-fi. Using "staggering" as a superlative isn't uncommon but if something is going to "stagger" it either took a punch to the gut or is a noncontiguous arrangement of things.
"Security" can be used in many contexts but it's rare to see "securities" used outside a discussion of investments/finance.
Math
The similarity measurement is accomplished as follows:
- Generate trigrams.
- Remove stopgrams.
- Intersect the trigrams of Post A and Post B.
This can be applied to post text and emphasis tokens and yield both a nominal intersection and a normalized one. I put these values get put in a datatype I call MultiscoreList that
takes an arbitrary number of score values and ranks the added items normalized for each column's min and max.
Iterating over the crawled web pages would look something like this:
-- Relative-- -- Nominal -- -- Keyword nominal -- -- Link --
Rel: 0.019969 nom: 26.0 keyw: 13.0 https://...
Rel: 0.014937 nom: 19.0 keyw: 9.5 https://...
Rel: 0.015353 nom: 19.0 keyw: 9.5 https://...
Rel: 0.043935 nom: 69.0 keyw: 34.5 https:/...
Rel: 0.025517 nom: 37.0 keyw: 18.5 https://...
Rel: 0.027312 nom: 44.0 keyw: 22.0 https://...
Rel: 0.029347 nom: 40.0 keyw: 20.0 https://...
Rel: 0.056619 nom: 173.0 keyw: 86.5 https://...
The final ranking would sort by an average of each column's nomalized value.
URL filtering
I quickly learned that the
most important component of this project is the url filter.
- The code's objective is to link the indieweb/smallweb/old web, not product pages, AI-generated garbage, or Web2 links that immediately hit a login wall. Filtering those parts of the internet before sending an http GET is the first line of defense against the normieweb.
- Web crawling is a limited resource, so it is beneficial to avoid any unnecessary crawls by divining meaning from the url.
- Storage is a limited resource, so avoiding gathering unnecessary post data is beneficial.
- The recommendation engine (in its current form) traverses every stored page, minimizing unnecessary post data is beneficial.
Domain blacklisting
There are some good domain blacklists out there. Marginalia has one. They can be tossed into a (large) set for a quick lookup. This list grew steadily as I crawled and examined the results.
Top-level domain blacklisting
|
|
From some crawler Rob linked me to. |
Top-level domains are a different story. I'd like to block *.affiliate-recommender.xyz but don't want to do the legwork of finding shop.affiliate-recommender.xyz, store.affiliate-recommender.xyz, uk-store.affiliate-recommender.xyz, etc. Now, it's trivial to do this using domain.endsWith(tld) or a regex, but
the O(1) domain blacklist check suddenly becomes O(n) as I'm checking each TLD blacklist entry against my url. Could I parse the TLD from an arbitrary url and check that against a TLD blacklist?
 Alex Martelli
Alex Martelli |
No, there is no "intrinsic" way of knowing that (e.g.) zap.co.it is a subdomain (because Italy's registrar DOES sell domains such as co.it) while zap.co.uk isn't (because the UK's registrar DOESN'T sell domains such as co.uk, but only like zap.co.uk).
You'll just have to use an auxiliary table (or online source) to tell you which TLD's behave peculiarly like UK's and Australia's -- there's no way of divining that from just staring at the string without such extra semantic knowledge (of course it can change eventually, but if you can find a good online source that source will also change accordingly, one hopes!-).
|
Apparently
Mozilla has a list of known suffixes but in this case I decided to just burn the CPU cycles. The discovered domains could be fed back into the set for quick lookup, but I was still looking at iterating through the TLD list for urls that shouldn't be skipped.
Page name
I found that these
page names can be safely ingored:
// Preceded by "/", end in "/" or "/index.htm[l]?" or ".htm[l]" and
// optionally have "#whatver" or "?whatever" after.
URL_SUFFIX_BLACKLIST_RE = {"terms",
"sustainability",
"legal",
"privacy",
"about",
"legal",
"account",
"contact[-_]?us",
"download[-_]?app",
...
If someone creates a page called
.../about.html that gets skipped it's not the end of the world and, well, that is my about.html page so maybe it's supposed to be skipped.
Though there are a lot of different types of de rigeur pages, they generally follow naming conventions.
Links only
Blogs typically follow the convention of a named page for each post and a monthly roundup of several posts (Wordpress with its ?p=1234 is an exception). The
roundup pages are duplicate/noise/bulky information and therefore should be skipped. That said, they're useful for harvesting links to its constituent pages. So, like ".*\/[\d]{4}\/[\d]{2}[/]?$" on the url will find these pages to stash in the 'ignore' list and harvest for links. The same can be said for home pages and '../links.html'.
PMA
This part of the code required a lot of logic, lists, regexes, and looking at data, but it's probably worthwhile. While my posts list and my ignored list grows with each visit,
the blacklist rules handily cordon off large chunks of the commercial web.
Other things added along the way
Canonical urls
Since www.site.com/my-journey-to-eritrea#hiking is the same as www.site.com/my-journey-to-eritrea is the same as www.site.com/my-journey-to-eritrea?ref=travelguide.com I do what
Google Search Console (and others) do and
query the canonical url, storing the others elsewhere to avoid hitting that page twice.
Data cleaner
Everything about this crawler/scorer evolved as it ran. I'd download pages that would later be excluded by blacklist and so
it was important to re-traverse the manifest and delete the offending files. Likewise my link backlog became cluttered with things like only-occasionally-relevant .edu links. They didn't warrant a blacklist rule, but occasionally flushing .edu and .gov and .ca kept the queue focused. Even more aggressively, I'd retain only things conforming to /yyyy/dd/.
NYI
This only works for me and is integrated in my SSG. To actually connect the personal web
I need a web front end so that any Thomas, Richard, or Harold can easily add external links to their site. It could look something like this:
|
|
|
Submit a post, receive a list of recommendations. A few defaulted values assist with formatting. The results could have report features for 404s, *walls, commercial stuf, etc. |
Seeding and search
Here's a slightly-pruned list of the top
keywords from my crawl corpus at n = 30,000:
Token Count
----------- ------
twitter : 5066
facebook : 3868
rss : 3121
log : 2736
github : 2716
projects : 2463
wordpress : 2461
app : 2319
javascript : 2219
linkedin : 2211
youtube : 2017
newsletter : 1870
games : 1780
mobile : 1648
cookies : 1555
error : 1495
mastodon : 1464
This excludes stopwords, years, stuff like that. Confirming my suspicions from above, the blogosphere seems to talk a lot about the internet, platforms, and web development. That's not great for my posts about PUBG video editing,
nightsurfing, and pool resurfacing - these will either have no links or heavily-shoehorned links. Similar content is out there,
it's just going to take more than 30,000 visits starting from webdevland to get there.
In theory, anyway. In reality I did what any good engineer would do to prepare for an underwhelming demo: I faked it.
Well, not exactly, I simply
seeded my crawl queue with links laboriously found by other means. It solved my immediate problem and hopefully added diversity to my initial link corpus.
Marginalia Search was a good starting point but it had little to nothing about 'Ducati' and 'Fire Emblem Path of Radiance'. A
Hacker News post that
Rob sent me listed a few alternative/indieweb search engines, my experiences weren't great...
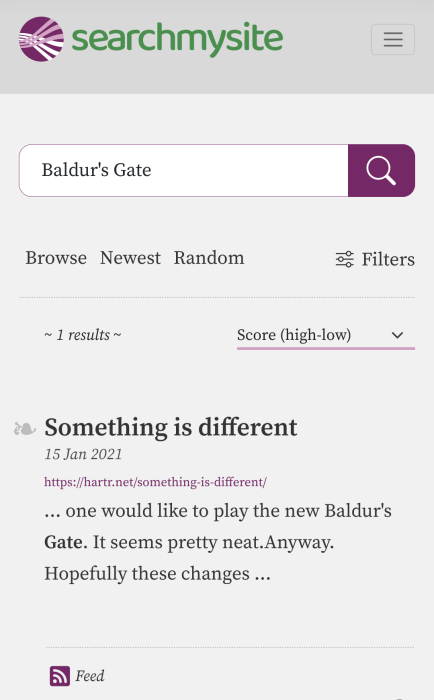
Searchmysite
I asked searchmysite about "Baldur's Gate" hoping it could match any of the older titles or the hot new installment. It yielded a single result.
Perhaps their business model is what's holding them back?
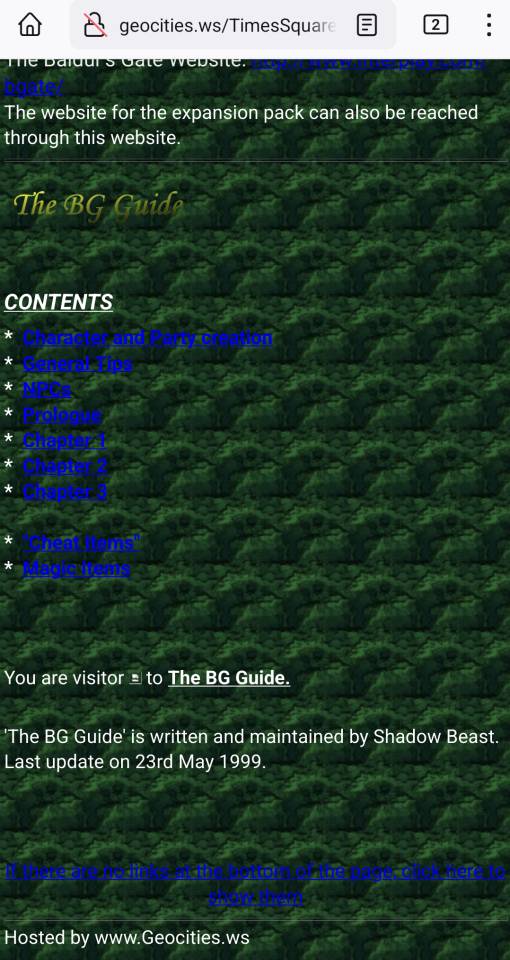
Wiby
Wiby returned more results for "Baldur's Gate" though none showed significant polish or recency. The first result was beautifully/terribly old web and last updated in 1999:
Bing AI search
Enough of this small-time nonsense. Microsoft's investment in OpenAI that
sent Google into red alert would surely meet my needs.
While a ranking algorithm might fail to overcome the onslaught of SEO, an AI-assistant would understand my query. Happily, Bing allows a handful of AI-assisted queries without creating credentials on the site.
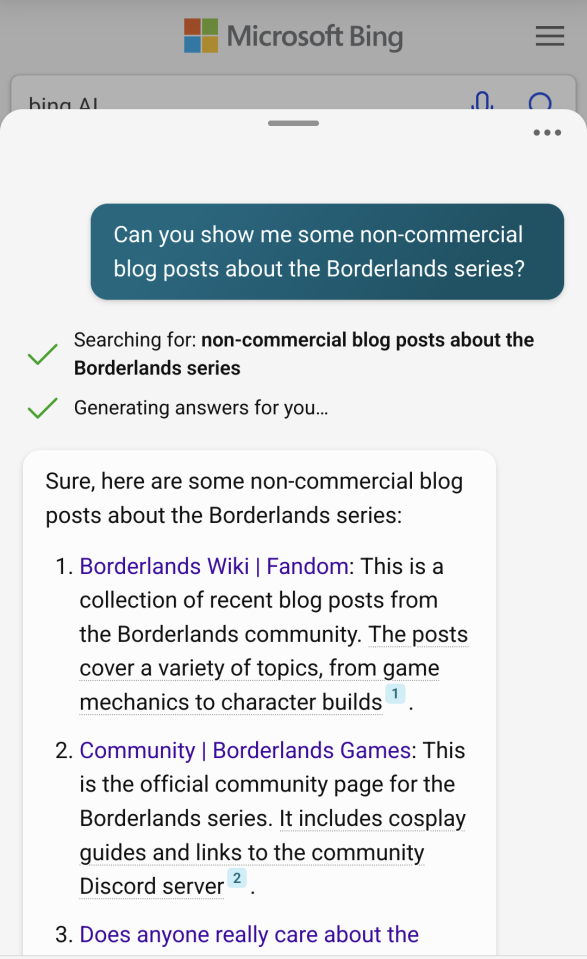
I tried my luck with the fertile fields of Borderlands fan-anything,
asking the chatbot for non-commerical blog posts (not entirely redundant, but enough overlap to tell it I meant business). I got:
- A fan wiki with a handful of internal microposts.
- The official forum.
- A Reddit post ranting about how story doesn't matter. Notably the GPT summary reads, "This post on the Borderlands subreddit discusses the importance of the game's story and characters. It argues that the story is what makes the game engaging and memorable".
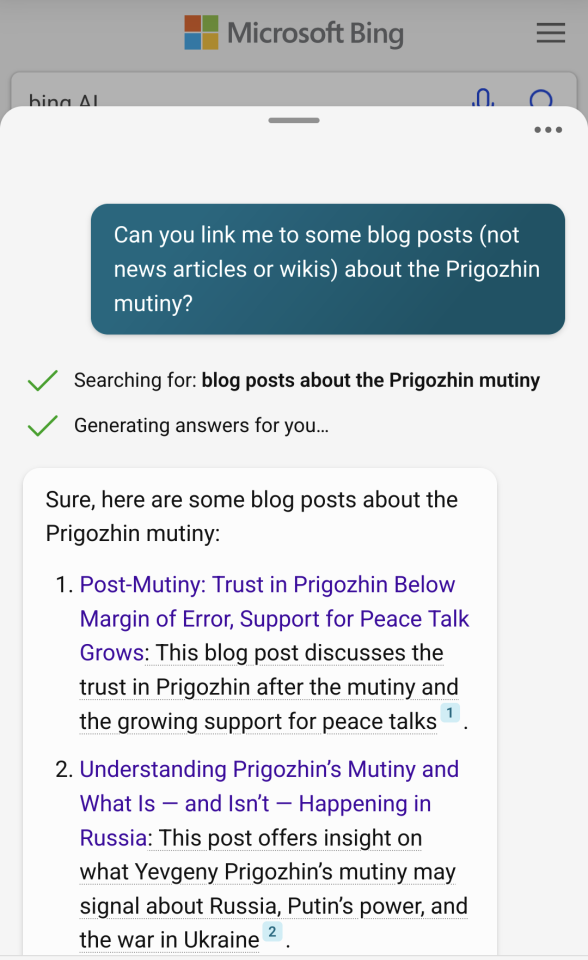
Switching subjects to the Prigozhin rebellion was a bit more productive. Bing provided
a few posts from the geopolitical centers at Harvard and Stanford as well as opinion pieces from the media.
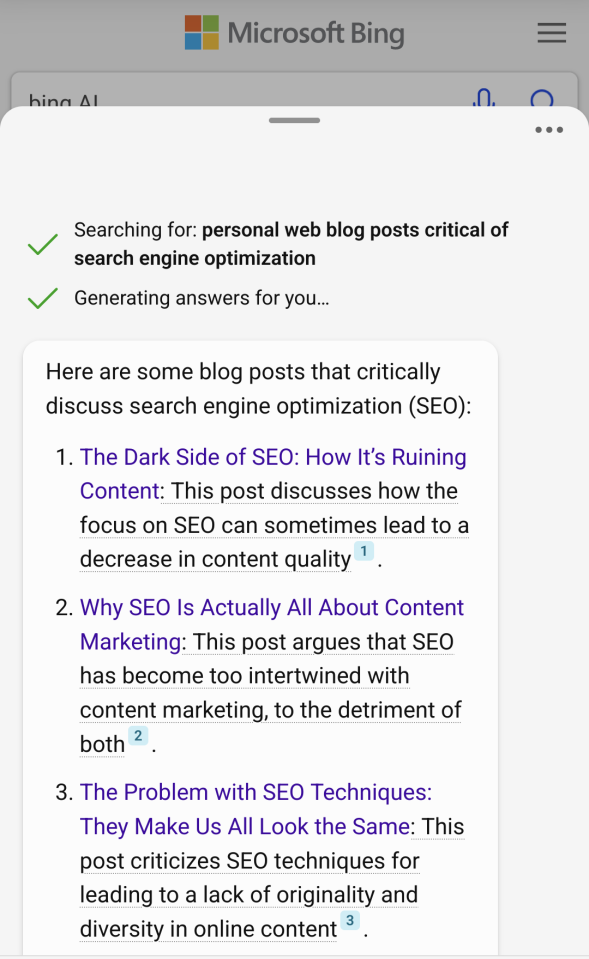
Things got a little weird when I
asked Bing AI to find critical discussions of SEO. I tweaked my query to say "personal web blog posts" hoping this would lead me to some snark or at least content below the major forum/media stratum.
"The Dark Side of SEO" somehow linked to a post titled "Blog SEO Best Practices" with all of the usual formulaic recommendations about keywords and page structure. Weirdly/amazingly the site managed to bait and switch Bing.
The next result which, per Bing AI, "... argues that SEO has become too intertwined with content marketing..." also linked to a hubspot.com post. Again,
it was just a pool of SEO vomit.
I'm not sure how Bing thought the posts were about the opposite of the thing they were about. While the posts contents could change, the urls for both posts are pretty explicit. A funny personal twist: we used to ask
RBB to summarize web links for us. Since native
ChatGPT couldn't fetch webpages,
RBB would do his best using just the url text. That would have actually been more accurate than Bing AI with Search Integration [TM, (c), and (R), probably].
What's next?
I think I'll work on
getting the crawl numbers up and propagating external links to more of my posts.
The saga of my
subsurface web linker feature request has finally hit the MVP milestone. After
some groundwork I'm now producing recommendations for similar content from other voices. It's still pretty foundational though; I've only indexed about 10k pages, my recommendation algorithm is unsophisticated, and I haven't run the recommender on anything but this month's posts.
But that's a story for another time.
The reading, research, and influx of links from my partner in crime meant
I was left with a trove of neat things to quote, link, and otherwise regurgitate. Some of it is thematically close to my link recommender project, so I'll start there.
Marginalia website similarity
I briefly thought my feature request had already been implemented when I happend upon a 2022 post from Hacker News mainstay Marginalia.
|
Marginalia |
This is a write-up about an experiment from a few months ago, in how to find websites that are similar to each other. Website similarity is useful for many things, including discovering new websites to crawl, as well as suggesting similar websites in the Marginalia Search random exploration mode.
The approach chosen was to use the link graph look for websites that are linked to from the same websites. This turned out to work remarkably well.
|
Already we diverge,
the Marginalia guy went with a Page Rank style of linking using a massive graph of hrefs. I've been working toward content-focused similarity since two people can write about
wood preservation or
Slay The Spire without linking each other - indeed, the lack of peer discovery is part of the problem.
That said, based on his ability to do math and create useful terabyte databases, I will defer to the wisdom of the Marginalia approach at the very least as an excellent parallel approach. And creating networks of peers makes a lot of sense, I used to link to
Connie and
KO and
Heidi,
when I find interesting stuff on the greater internet I often quote it and link it (e.g. right now). Following links is a big step up from blogrolls and links to friends.
I'm curious what my own peer graph would look like. Based on
Rob's content analysis,
my top linked domains are Reddit and Flickr. This is an accurate reflection of my interests in that I like photography and (decreasingly) democratized content with (decreasingly) robust discussion. But also my site is nothing like either of these and Flickr is only a frequent href from this site because I used to use it for image hosting.
|
Marginalia |
In plain English, this service looks at which websites link to a particular target website, and then it ranks websites that are popular among those linking websites using a method commonly used in recommendation algorithms.
In technical jargon, it reinterprets the incident edges in the adjacency matrix as sparse high dimensional vector, and uses cosine similarity to find the nearest neighbors nodes within this feature-space.
|
To complete my book report on Marginalia search, similarity is scored using vector math.
Ethics
|
Marginalia |
As a whole the feature shares a lot of similarity with how you would construct a recommendation algorithm of the type "other shoppers also bought", and in doing so also exposes how creepy they can be. You can't build a recommendation engine without building a tool for profiling. It's largely the same thing.
If you for example point the website explorer to the fringes of politics, it will map that web-space with terrifying accuracy.
|
I initially read this and thought, "how could this be used to profile web surfers clicking on recommended links?". Then I realized he was referring to the blogger/publisher/content creator being involuntarily associated with peers - guilt by association.
|
|
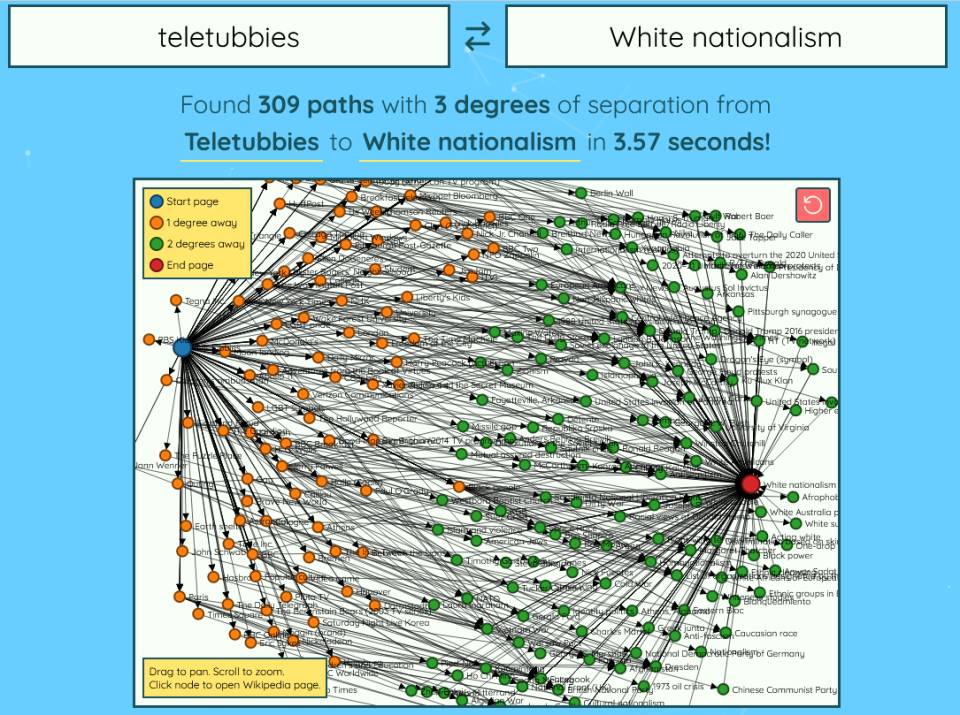
Source. This is a Wikipedia a->b tool that is conceptually similar to Marginalia's similarity graph. |
The guilt by association thing is a reasonable concern. Naively, you can pretty easily distance yourself from unsavory content by simply not linking to unsavory content. But unless you thoroughly vet the authors of your links,
you're bound to become a second- or third-order associate of something unpleasant. And, of course, hrefs don't understand amusement or sarcasm. If I post a link to
/r/phunware and say "hey, check out these assholes", the link won't capture that context. Similarly, while I enjoy a well-written greentext, I'm not really into most of what /b has to offer.
Then there's inbound links, over which a site administrator has no control.
|
Marginalia |
qanon.pub's neighbors
Note again how few of those websites are actually indexed by Marginalia. Only those websites with 'MS' links are! The rest are inferred from the data. On the one hand it's fascinating and cool, on the other it's deeply troubling: If I can create such a map on PC in my living room, imagine what might be accomplished with a datacenter.
You might think "Well what's the problem? QAnon deserves all the scrutiny, give them nowhere to hide!". Except this sort of tool could concievably work just as well as well for mapping democracy advocates in Hong Kong, Putin-critics in Russia, gay people in Uganda, and so forth.
|
To be fair, I'm sure this capability exists in more than a few places.
Another perspective
There was
a neat post that made it to HN about an internet subculture that has historically had the same concerns expressed in the Marginalia post. We'll get to that part in a moment, I'll let the author get a few words in about the state of the indieweb/old web/smallweb/personal web:
|
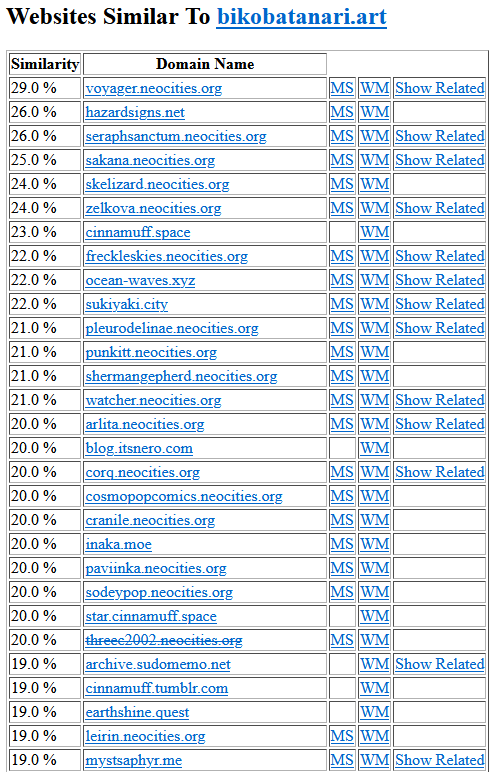
bikobatanari |
The Personal Web, to many people, only exists in a select few places. It could be solely sites on Blogspot, or Neocities, or some other adjacent platform, and that to them is the "Personal Web". However, once you've exhausted these places and found the sites that you find interesting, it's extremely difficult to figure out where to go next-to go to some unknown territory that you don't even know exists.
For myself, I've browsed Neocities for what seems like four years now as of writing this. I've seen many sites come and go-some plenty interesting, and others not at all. And even now, with plenty of sites that I don't recognize, I've become rather jaded. It's hard for me to find sites that pique my interest anymore-and if they do, it's hard to find them actually being updated or not be completely barren. All of this is what led me to going on excursions to places that not many people have gone to.
This is difficult in and of itself since funnily enough, Neocities users tend to link to only Neocities users and no one else. Despite many of its users being against walled gardens, it ironically became one itself.
|
So Bikobatanri fired up translation software and (as an outsider) embarked upon
an expedition into the doujin web.
|
bikobatanari |
From what I've seen, [doujin sites are] structured by various search engines whose sole purpose is to index personal Japanese sites and nothing else; by "index", what is really meant is people register their own personal websites onto the engine-sort of like a glorified link directory. Its scope is even narrower than that of Neocities and other hosting platforms because sites with more formal contexts (such as business sites) are not even allowed in these spaces.
This got me curious then: how differently do people over in the East Asian sphere (primarily Japan) handle personal websites compared to the West?
|
Site design and
SEO implications? You had my curiosity, now you have my attention.
|
bikobatanari |
Something that I've noticed in general is that the personal sites over there tend to be very creations/product focused. That is, their sole purpose is to show off things that they've made, rather than embody some sort of persona.
Even the site topic distribution makes this evident. The front page of a search engine that specializes in doujin sites called [Yorozulink when romanized] has sectioned off registered sites into categories, and the visual arts trumps practically every other category. An overwhelming majority of these sites' admins post illustrations, lots of them post their own mangas (original or derived from an existing series), write novels and stories, and indulge in a lot of other creative hobbies. Personal diaries and blogs do exist, but I don't think it's as ubiquitous there as it is compared to the West.
|
Ah, doujin sites are like portfolios and the community has its own indie search engines.
|
bikobatanari |
Usually the design is all coded by hand, and templates are, in a way, frowned upon. But relating to the creations-focused philosophy that a lot of these sites adhere to, the design of many of these sites are actually rather... tame. Minimalistic, even. Portfolio-like. Designs that showcases their work rather than ones that potentially take away attention from it. This is despite the fact that they're actually not portfolio sites.
|
Okay not portfolios. Semi-portfolios. The author goes on to discuss
the guestbook protocol which is very much the opposite of the like/retweet/rant aesthetic of social media sites. And it doesn't stop there:
|
bikobatanari |
A term which I've encountered quite a bit on Japanese personal sites [translates to] simply "search avoidance".
Essentially, there are plenty of personal sites that go out of their way to make sure their space doesn't get spotted or picked up by search engines; and not the search engines that index these types of sites mind you (like the ones I linked to in the beginning of this article)-they're explicitly talking about search engines like Google, Bing, Yahoo!, etc.
These sites will have a disclaimer saying that their site "avoids search", and more often than not they will also add an additional disclaimer saying that their site is not allowed to be linked on SNS (basically their shorthand for social media).
|
The anti-timeline
|
Amy Hoy |
[In the 90s], we didn't have platforms or feeds or social networks or... blogs.
We had homepages.
|
From Bikobatanri I found another post with some old web/doujin overlap. The striking (yet obvious) observation made therein is that
blogs are the internet's true villain:
|
Amy Hoy |
Homepages had a timeless quality, an index of interesting or useful or relevant things about a topic or about a person. You didn't reload a homepage every day in pursuit of novelty. (That's what Netscape's What's Cool was for!)
Chronological content was in the minority.
The Internet at the time was largely populated by academics, professionals, and college students. Not everyone had the desire to publish their angsty poetry, sexcapades, or surfing habits on a daily basis; the other limiter on chrono-content was the sheer time and energy it required. Diarying was a helluva lot of work. First you had to have something to say, then write, edit it, format it, add clip art, edit your index.html, edit any prev/next links, check those links, and lastly, upload the files.
|
This sent me into
a vortex of personal crisis, have I forgotten my roots? From 2000 until 2007 this site was a time-agnostic photo portfolio with handwritten html and the occasional angsty sexcapade. Argh, I already did it again, talking about 2000-2007.
|
Amy Hoy |
And once you've had a taste of effortless updates, it's awfully hard to go back to manual everything.
So they didn't.
And neither did thousands of their peers. It just simply wasn't worth it. The inertia was too strong.
The old web, the cool web, the weird web, the hand-organized web... died.
And the damn reverse chronology bias - once called into creation, it hungers eternally - sought its next victim. Myspace. Facebook. Twitter. Instagram. Pinterest, of all things. Today these social publishing tools are beginning to buck reverse chronological sort; they're introducing algorithm sort, to surface content not by time posted but by popularity, or expected interactions, based on individual and group history. There is even less control than ever before.
|
Bikobatanari's take on this:
|
bikobatanari |
Another issue which holds for platforms with this type of structure (especially IG, Twitter, and Tumblr) is that looking back through another person's archived works is an absolute chore. If you want to look for a particular piece of work in someone's account, have fun wading through years of work in reverse chronological order just to find it. Because of this, people just end up resigning to have content spoonfed to them through the feed, as opposed to searching for all of the hidden gems that have long since disappeared from the public eye. It's a real shame, because there are possibly plenty of great works that will not be seen ever again because it's such a nightmare digging through all of this stuff just to find something specific.
|
They're not wrong. I think
I've subconsciously seen this in my own site and worked toware creating alternative means to navigate it. E.g. the
Slay The Spire page shows other titles sorted (generally) by similarity. Navbar-linked pages present indexes to
travel posts and
lists. It's not quite a 90s or doujin site, but it doesn't require eight hours of scrolling to see something from a year ago (@Twitter).
Bikobatanari seems to have had the same crisis:
|
bikobatanari |
In a way, this article has influenced my website's structure in some way. If you were here to see my website a few months ago, you would find that my articles page used to be entirely in reverse chronological order. It wasn't until November that I started categorizing my articles into separate topics, and I think that small little change has done wonders for both myself and for those who want to read something more specific to their interests.
The more I think about it, the more I see that the rise of chronologically ordered content for all of these platforms has impacted content creation in a way which I think is detrimental. Not only has it affected a piece of content's lifespan and long-term influence, but it has also normalized a structure which doesn't suit the majority of content in the first place.
|
In defense of the feed model I should say two things:
- It reduces the frequency with which you see something twice.
- Even timeless things have a birthday. It's not a bad thing, so long as its identity isn't inseparable from a moment in time.
|
bikobatanari |
I do want to note that the feed itself isn't bad. It has its uses. Blogs and journals work perfectly fine with a feed. The main gripe that I have with it is that with the normalization of using social media as a platform for content creation, the feed became the structure which everything was forced into, regardless of what type of content it is.
|
Yeah,
I will continue to use this format and continue to provide navigational wormholes. And I'll think long and hard about adding a recency variable to my external link recommender.
Some good old-fashioned ranting
The real value of the web's fringe sites is that
you occasionally come upon something profoundly entertaining. And so apropos of nothing, here is the experience of some random dude at a couple of tech tradeshows.
Note: these quotes and the post itself are best experienced with a mental picture of Lewis Black in your head.
|
Ludic |
One of the keynote speakers runs a major customer loyalty program, which as a non-specialist I believe is code for "we sell all your purchasing data in the hopes that people who can't do math don't realize our rewards are worth like $200 over your entire lifespan". If you are a specialist, I will accept corrections but also, I dunno, fuck you on principle I guess. You might not deserve that, but it's a Monday and I just had to go through standup.
This person breathlessly took the stage and spoke happily about how they've had almost 10% year-on-year growth because of the crippling increases in rent and groceries driving the working class to seek savings wherever they could.
Very cool and normal, and also fuck you on principle, even if it isn't a Monday.
They then continued to talk about the thrill of seeing that family finally purchase that vacuum cleaner that was always aspirational.
Again, fuck you, and also I hope you fall down a flight of stairs. I swear to God, I can't even imagine what kind of defective software you have to be running in your brain to be that tone-deaf, but I was deeply concerned to see this is what our bajillionaire class is doing. It's a super concerning blend of being a complete sellout and too goddamn stupid to even hide it well. How hard is it to get on a stage without sounding like a Disney villain?
|
I normally try to tie together the block quotes with some commentary, but in this case I'm just interrupting.
|
Ludic |
I think the worst part was realizing that this didn't flag for some people in the audience, even techies. Some part of their brain just turned off and went "10% year-on-year growth? That's money. And look how important that person on the stage is! I wish I got attention!"
|
On the tradeshow floor:
|
Ludic |
I am not sure how to describe this rationally so I'm not going to try, but the air felt like someone had been operating some grease-filled humidifier, and I think this hit me because I walked in and immediately saw the event was sponsored by some dipshit crypto application. The funny thing is that rather than having blind hatred, I read Mastering Ethereum for a bit because it would have been so convenient if I could actually just print money by finding some crypto use case that I'd be morally okay with, and I just couldn't. So rather than blind hatred, my hatred has intense visual acuity.
|
|
Ludic |
We were then approached by a guy, who we will call Henry, that immediately blasted us with totally unsolicited advice on how to get our own business off the ground... he makes sure that we have his cards as we spend twenty minutes trying to extricate ourselves.
He seems like he learned his social skills from Dale Carnegie, which is forgivable, but he thinks he's better than us, which is possibly but true but not forgivable.
|
Thank you, internet. Thank you, blogosphere.
He has another good post on corporate decisionmaking, "The Failed Commodification Of Technical Work":
|
Ludic |
That's right, there's a whole genre of corporate fanfiction out there. Was it useful to read? Yes. Does it miss some of the real barriers to organizations improving? Yes, which I should talk about in another article. Was it cringe-inducing at points? Hell yes.
|
Moment of zen
|
|
Source. After Burner and RBI Baseball are on my desert island list. |
At
the crossroads of early console gaming and DRM there's a story about why unlicensed games were rumored to blow up your Nintendo.
|
Nicole Express |
The other thing that makes Tengen stand out is how they broke the Nintendo's lockout chip. Modern consoles maintain their lockout using cryptography. But in the 1980's, that would get your console classified as a munition, and the NES' 1.7MHz CPU would struggle to implement anything regardless. Plus, cryptographic locks had no legal force at the time; this wouldn't be the case in the US until the 1998 Digital Millennium Copyright Act.
So instead, Nintendo developed a small microcontroller, which implements a program of sending random numbers back and forth. The microcontroller in the console compares with one in the cartridge, and if their numbers don't match the expected pattern, it resets the console every second, preventing gameplay. The chip is configured so the program can't be dumped easily, and if you do dump it, the program is protected by copyright law.
Here's Camerica's 1992 release Micro Machines. You might notice some circuitry in the corner; what this is is actually something we've covered on this blog before, a charge pump that produces a negative voltage from the console's 5V input. When the console turns on, a negative voltage spike is sent down the reset line of the lockout chip, frying it long enough to break its program and cause it not to reset the console.
|
In this post:
- Finishing Act II of Baldur's Gate 3
- Starting the much-anticipated sequel to Remnant: From The Ashes
Screencaps throughout, plot spoilers avoided.
BG3: on to Act III
I finally made it to Baldur's Gate (city) in Baldur's Gate (game). Well, just the suburbs I think. In August
I complained about how the villages have named NPCs with short, cinema-view dialogue that goes nowhere. There are considerably more of them in the city but it's easier to (successfully?) navigate them since I have a better idea (quest log) of what's going on. I am, however, concerned that by walking past so many characters I might be missing out on a fun or useful side quest.
But let's return to Act II since I just started Act III.
Atmospherics
I'm relieved I didn't get to the Shadow-Cursed Lands by way of the Underdark because that seems like simply too much darkness for my taste. I don't mind a little horror but
it's refreshing to now be in an otherwise-vibrant city with political horror rather than piles of corpses and hp-draining shadows.
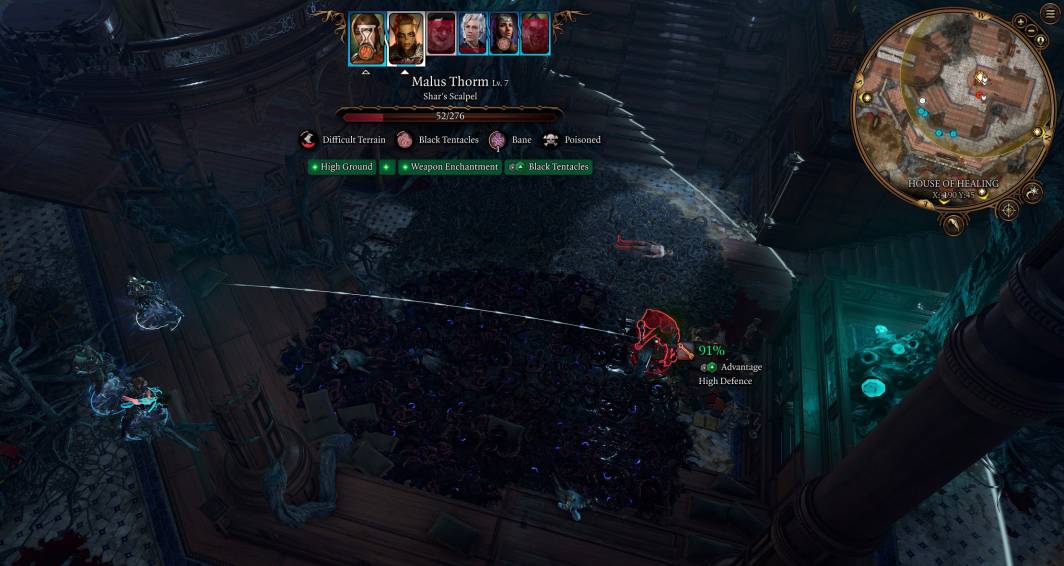
Minibosses and bosses
While the permadark/permabloody environs got a little tedious,
dialogue-having enemies like Malus Thorm and Balthazar make for an interesting journey through the shadows. Ketheric, Gortash, and Orin might be too busy being evil to have the personality of a Thisobald Thorm or Yurgir, we shall see.
Allies and camp
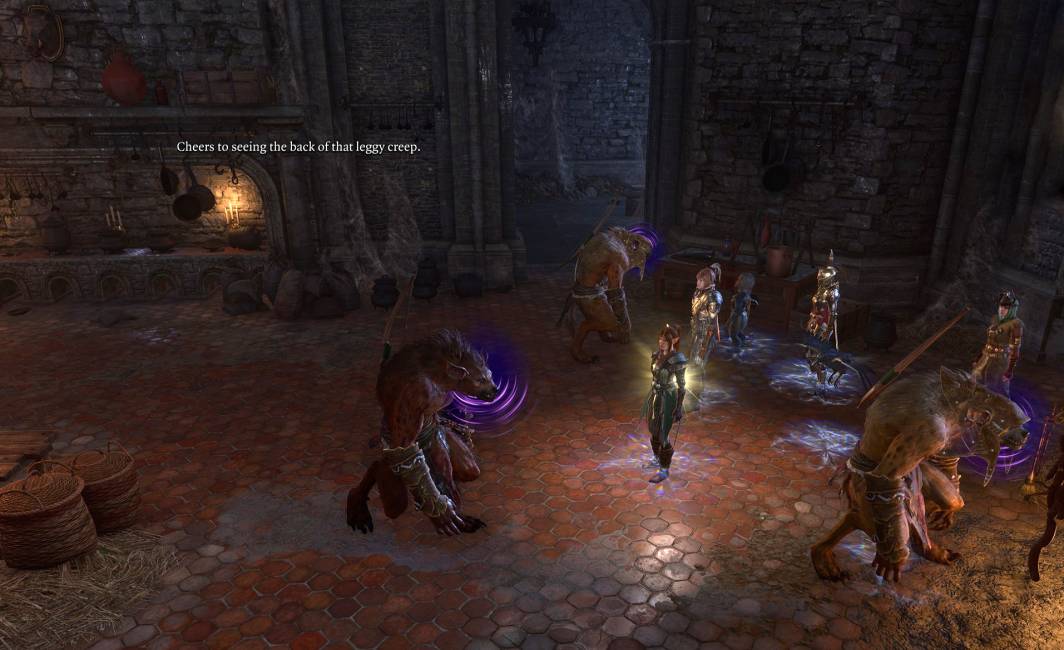
I was unimpressed when, on the heels of convincing Lae'zel to turn from her life of unquestioning servitude to a god-queen, I convinced Shadowheart to turn from her life of unquestioning servitude to a god-queen.
Why do I keep winding up with these cultists when there are hilarious djinns and noble carrier pigeon commanders out there in the world? On the plus side, all of the other recruitable companions aren't like this.
After one and a half acts of leaving the C-tier characters (Wyll, Karlach) on the bench, I've started rotating everyone in. Sticking with my besties wasn't entirely because I don't like particular characters/classes, for a while
I didn't have enough/correct equipment for everyone and trading it in and out is too tedious. I'm hoping NG+ fixes this.
I didn't expect camp to get so crowded.
A surprising number of un-killed NPCs ask to set up in camp and provide a little bit of dialogue and maybe some endgame benefit. The more the merrier and/or meatshieldier if it comes to that.
Convergence
Story/choice-heavy games are all about doing the right thing or the clever thing or the laborious thing to affect the world in a manner of your choosing. Sometimes your choice gets you unique dialogue, sometimes more reward, sometimes different loot, and sometimes there's a consequence down the road. To continue my point from the last section, NPCs with more than one line of dialogue in BG3 fall into three categories:
- You kill them.
- You give them a spot in camp.
- They say, "Okay later, gator. Omw to Baldur's Gate, maybe we'll meet again".
That's a little hyperbolic to drive home the point that
I'm anticipating a lot of reemergent plot arcs when I get to the city center. It could make for a busy calendar but one full of story/choice payoff. And I do hope that at least some of my 'good' choices come back to bite me in the ass.
That brings me to a good fourth-wall chuckle.
An NPC asks (paraphrasing), "Why did you help us?" One of the reply options, "For the experience, really."
Battle
I'm almost proficient in combat. By far
the most dominant tactic I've found is to slow/bleed melee characters with vines and/or dark tentacles. Most enemies have a jump but these spells have a large area of effect and can be cast by multiple squad members. Now that I'm cycling through the whole squad each day, the spell slot limitation isn't as hefty as it was in the early game. And now that I'm using Wyll, I have some appreciation for the warlock class's regenerating spell slots.
|
Some NPC |
I always knew I'd die at a circus.
|
A little more Act II
Remnant II
Remnant: From The Ashes was a sleeper that me and J had a lot of fun with. It was
like The Division crossed with Borderlands crossed with Destiny set in a weird postapocalypse that was as confusing and lonely as
Warframe. The sequel was released recently so we've worked it into our schedule of trying to beat the
Gunfire Reborn final boss.
I can't say too much at this point except, first, that all of the aesthetics of From The Ashes are there - gunplay, loot, impressive environments. Where the first game had a series of worlds with segmented maps, at least some of R2 takes the overworld/underworld approach you see in
The Division and
Destiny.
So yeah, excited about this one.
|
Infopost | 2023.12.02
|
|
 |
|
|
|
There isn't a lot of visually-compelling content in this one so I grabbed a BG3 scene that vaguely aligns with this post. |
What happened this week?
- "Don't blackmail me with money."
- AI product reviewing rears its ugly head, again.
- Already renowned for its efficacy, the SEC looks like it may be kneecapped by the Roberts court.
"Tell that to Earth"
"Elon says 'Go fuck yourself'". That was the headline at most tech/finance news sites. It's not a bad quote, but it leans too heavily on profanity and confrontation. And it's not original.
I much prefer another quote from that interview, "Tell that to Earth". *Chef's kiss*. It's fresh, it's dumb, it's Elonny. I'll heap more praise on it in a minute, but let me begin by saying I don't aspire to post about every bit of Elon drama. Nor do I think his outburst was remarkable or underreported. But
this story had a couple of gems so I will retell it and point at the cool bits.
Once again, from the top
If you don't F5
Ars all day or are reading this sometime after next week when everyone has stopped caring,
Elon Musk made a media splash when he told Bob Disney to 'go fuck himself' for pausing Twitter ads. Iger's reasoning was that the X CEO posted the following:
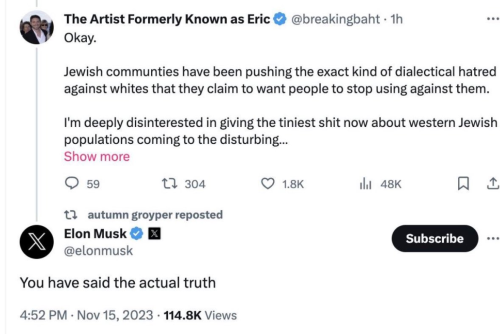
Initially, there was some debate about whether the @breakingbaht tweet was overt
replacement theory or an extremely narrow statement directed and specific examples of xenophobia. It would appear that this rationalization was entirely disingenuous; it quickly disappeared when people began looking into @breakingbaht himself and Elon apologized for calling the post 'truth'.
Musk fortified his remorse with an 'apology tour' to visit Israeli leaders and the ADL. He then deployed
his tried and true tactic of creating a more favorable controversy to crowd out the less favorable headlines, saying basically that
he believes Pizzagate.
He could have chosen worse, I suppose.
Pizzagate is controversial enough to eclipse the earlier conspiracypost while not targeting any specific group because, well, to paraphrase the actual Pizzagate gunman, "Oh, Comet pizza doesn't have a basement, I've made a terrible mistake." Elon deleted that tweet after the headlines were inked.
It probably worked on media consumers, but prestige X advertisers didn't announce their return. And so Elon had his gfy moment.
Musk may have been authentically frustrated that Apple, Disney, and NBC would look unkindly on racism. The lack of ad revenue may mean he's looking at another apology tour, this time to Riyadh. I don't know, if I was reading this in a novel I'd consider it weak writing. It's been
only a year since Elon unbanned everyone Twitter and then re-banned Kanye for... *checks notes*... antisemitism.
|
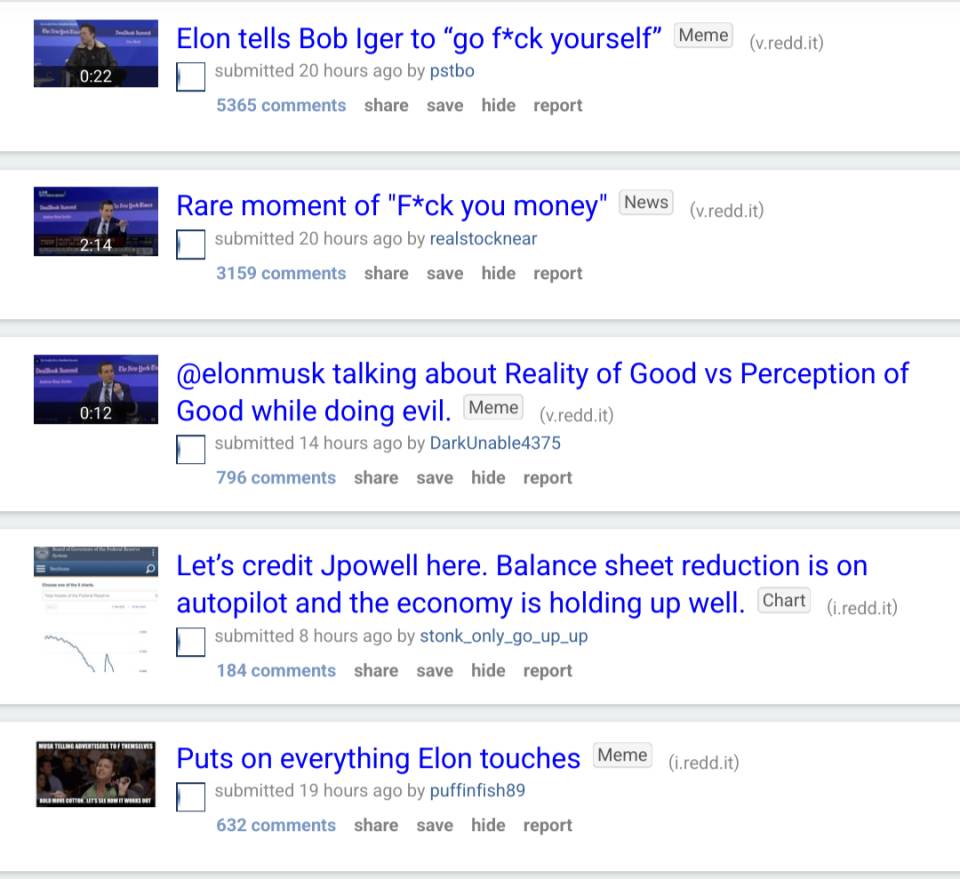
|
|
WSB shouldn't be considered a proxy for mainstream chatter but in this case it certainly was. |
Perhaps Elon's Disney feud is entirely contrived, either as a third-stage headline blitz or to broadcast some other point.
I reckon there's more
The commentary
I read from Elon fanboys and Texas voters was, "Yeah Elon! Tell that woke left to fuck off!" Because of course the "woke Disney" thing wasn't a momentary Florida beef, the label has stuck and The Mouse is now woke like Bud Light, the NFL, and Carhartt. If he does nothing else with in his political career,
Ron DeSantis managed to successfully brand a ancap-curious megacorp as 'woke' simply because it was maximizing its consumer base.
Returning to the gfy interview:
|
|
MUSK: Absolutely, totally, look. Actually, what this advertising boycott is going to do is it's going to kill the company. And the whole world will know that those advertisers killed the company and we will document it in great detail.
SORKIN: But those advertisers, I imagine, they're going to say, we didn't kill the company.
MUSK: Oh, yeah. Tell it to Earth.
SORKIN: But they're going to say -- they're going to say, Elon, that you killed the company, because you said these things and they were inappropriate things and they didn't feel comfortable on the platform, right? That's what they're doing to say.
MUSK: Let's see how Earth responds to that.
|
Elon's
$40B Twitter offer in 2022 confused a lot of people, including the Twitter board. The traditional explanation of wanting to avoid a $1B judgment seems reasonable enough, but maybe this is it. He thinks so highly of the microblog service that he's willing to massively overpay for it and, when facing an existential crisis,
thinks that all of Earth will harshly judge companies for not propping it up with advertising revenue.
It's probably not that but would be hilarious if it was. Maybe Elon has become unstuck in time and
is remembering the year 2042 when X (the everything app) is the world's town square, rideshare service, and banking/payment app. And so when Xer existence is threatened, all of Earth unifies and calls upon large companies to give it advertising money.
It's probably not that either, but maybe more plausible? Most plausible of all:
Elon is just conditioned to fall back on 'Earth' as an argument of last resort when talking about electric cars, space colonies, and brain implants (effective altruism, you wouldn't understand). He didn't realize that Earth already has a bunch of competing services and nobody's going to blink when the eXit happens.
Great replacement, pizzagate, "my pronouns are prosecute/Fauci", purchasing a social media platform -
it's pretty clear that Elon's running for Texas governor in 2026. He telegraphed it rather overtly with his visit to their border to "express concerns about immigration" and has courted all degrees of conservative ideology. Meanwhile Greg Abbott has alienated the center-right and people who like utilities in winter. So the time is right to plant the seeds of a campaign. And he stands to gain quite a lot from holding the office: Musk and his businesses operate heavily out of Texas, as does Mohammed bin Salman.
So "tell that to Earth" and "Governor Musk" are reasons #1 and #2 for mentioning gfygate.
#3: "Please take a moment to bask in this profound thought leadership"
|
CNBC |
In the memo sent Thursday, [X CEO Linda] Yaccarino told employees that the X owner "shared an unmatched and completely unvarnished perspective and vision for the future."
She urged employees who did not watch the interview to "please take the time to absorb the magnitude and importance of what we're all a part of. Because that's exactly what I wanted to focus on with you today."
|
Amazing.
"The de facto CEO told our income sources to fuck off for not supporting antisemitism*, this just proves how important the work we do here is." Like, I'm used to getting negligently-positive messages like, "here's why partnering with China is a huge business win" and "Workday is an amazing platform used by such prestigious companies as Walmart". But this one is a masterpiece of the C-suite trying to make lemonade out of cancer.
*And not just casual antisemitism. Claiming that there is a global effort to eliminate all white people is a special brand of antisemitism that stands shoulder to shoulder with white supremacy and tinfoil-tier conspiracy theory.
AI in (non-)journalism
In October I
posted about
a product review site affiliated with traditional news media that was caught using AI to generate reviews. The takeaways:
- It most definitely was AI-generated and companies need to realize that many internet users know how ChatGPT talks.
- The articles in question were for product reviews outsourced to a company called AdVon. At a glance, the articles didn't appear to be marked as outsourced or advertising content, so it's tough to consider the site to be anything approaching journalism.
- The publication (called Reviewed) said they were assured by AdVon that the content was not AI-generated but may not have asked if "not AI-generated" meant AI wasn't used at all.
Kevin sent a recent
article about
Sports Illustrated being caught doing the same thing with the same AdVon vendor.
|
Futurism |
Regardless, the AI content marks a staggering fall from grace for Sports Illustrated, which in past decades won numerous National Magazine Awards for its sports journalism and published work by literary giants ranging from William Faulkner to John Updike."
|
Like a lot of journalism in the post-subscription era,
the article describes the incident in the most dire of terms. Sports Illustrated (the magazine) doesn't have AI writers. "Sports Illustrated Reviewed" with its conspicuous banner reading "we get money when you click our product links" used AI-generated content. I didn't look into it, but I suspect William Faulkner and John Updike didn't write product reviews for an online publication under the SI brand.
I'm an extremely sophisticated reader, so I know when a link from Sports Illustrated proper has taken me to their product reviews section. The graphic at the top changes. The content moves from college football minutiae to articles about off-brand sports equipment. Similarly, I know when a front page CNBC link about "the five best new credit cards" has taken me to their "Making it" section. I daresay I even have a good idea about the nature of the content simply from the link title (about signing up for a new credit card).
I don't like that news media mixes fake articles with their real content but I realize that they (probably) have to do it to keep the lights on. So Futurism isn't wrong to take issue with AI-generated product reviews,
we're just not yet on the cusp of seeing the NYT and BBC and WaPo's news desks being staffed by HAL and Bender and TayTweets.
The Arena Group and AdVon going by truck stop rules
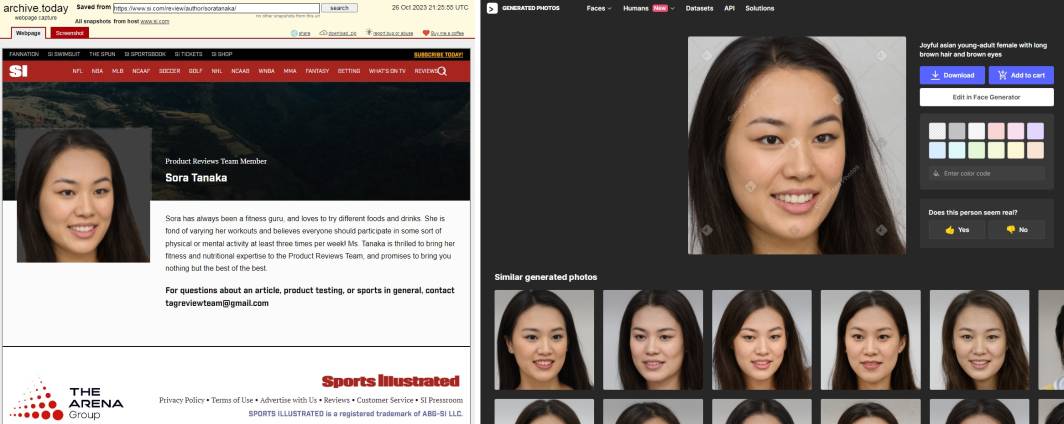
The Futurism article tracks down the
AI-generated headshots used for the AI-generated writer profiles creating the AI-generated product reviews. All they need is AI readers to purchase the advertised products.
|
Futurism |
It sounds like [SI parent company] The Arena Group's investigation pretty much just involved asking AdVon whether the content was AI-generated, and taking them at their word when they said it wasn't. Our sources familiar with the creation of the content disagree.
|
It's the same story as Reviewed dot com and its parent, Gannett. The review site has some semblance of journalistic integrity, the affiliate content vendor has none, so
AdVon absorbs the blame and continues dumping generated, SEOed content on the web.
SCOTUS and the SEC and administrative law
 Snoo-27151 Snoo-27151 |
The case that could destroy the US government and have disastrous consequences on the SEC
The SEC enforces the basic rules that make stock markets work. Without it, stock issuers and dealers would lie-with disastrous results. One needs only to examine the rampant fraud, contagion, and meltdown in crypto markets last year to see what an unregulated securities market looks like. More generally, if Congress cannot delegate to agencies, it cannot govern. Congress could never and has never written rules specific enough to anticipate all eventualities. This is why Congress delegated power to the SEC in the first place. Finally, and most dangerous, ending independence for internal agency adjudicators would undermine the rule of law. Without independence, adjudicators would be beholden to the politicians who oversee agencies. Unscrupulous presidents would use agencies to punish their opponents and reward their allies. This would do more than turn regulators into political handmaidens; it would destabilize markets, stifle growth, and inevitably lead to financial crises.
- The Atlantic
|
I could have quoted The Atlantic directly or chosen a more succinct summary but
the top comment was interesting:

|
/u/IndependenceNo2060
Yeah, the SEC plays a crucial role in maintaining market integrity. Without it, we'd have a Wild West situation where the rich and powerful could exploit the system for their own gain. We need a regulator to keep things in check and protect the average investor.
|
|
|
/u/Razor1834
Honestly thought this was VisualMod. [Ed: who has been providing GPT responses since before ChatGPT]
|
AI creeping into my scotusposting
Let's come back to the SCOTUS thing but pause enjoy this
overlap of AI-generated content, investing, and the Reddit/WSB brain drain phenomenon. The top comment was/is a meaningless GPT creation, people immediately called it out, and it has remained the top comment to this day. The fact that it wasn't downvoted to oblivion perhaps says something about the state of the site/sub.
I was surprised to find that
/u/Independence2060 is active and not banned. Its
recent comments don't show a hint of humanness, its posts are all bad AI art. It checks for content removal and
shadowbans. I guess this is a
Reddit tip-farmer.
What was Merriam-Webster's word of the year again? Oh yeah, 'authentic'.
 Im_A_MechanicalMan Im_A_MechanicalMan |
> The Atlantic
Well there's your problem! But CNN, that you actually linked, isn't much better. These are biased opeds trying to sway your view one way or the other.
|
On the other hand,
maybe authentic commentary isn't so great.
SEC v. Jarkesy
Let's get back on track.
George Jarkesy is a conservative talk show host and (small time?) hedge fund manager who will soon have his name attached to the death of administrative law. Back in the Obama years he established a fund through his firm 'Patriot28' wherefrom he illegally extracted more than half a million dollars of investor money. Jarkesy accomplished this by
overvaluing the assets under management and thereby raking larger-than-appropriate management fees.
The SEC solved the problem; they investigated Jarkesy, tried him in an administrative proceeding, and meted out justice. Jarkesy was fined for being a douchebag and required to return the ill-gotten gains so that his investors could go buy MyPillows and contribute to Steve Bannon's border wall.
The system worked. The theoretical problem with the debacle (other than the fraud) is that
the administration of justice was handled by the SEC (an executive entity) and not an Article III (judicial branch) court.
|
CNN |
The federal appeals court ruled in favor of Jarkesy on three separate constitutional claims. It held that certain of the SEC's proceedings deprive individuals of their Seventh Amendment right to a civil jury. In addition, the court said that Congress had improperly delegated legislative power to the SEC which gave the agency unconstrained authority at times to choose the in-house administrative proceeding rather than filing suit in district court. The court emphasized that under precedent, Congress can only grant regulatory power to another entity if it provides an "intelligible principle" to guide the proceedings.
"The Constitution," the court held, "provides strict rules to ensure that Congress exercises the legislative power in a way that comports with the People's will."
|
And so we have both
a civil rights issue and a nondelegation issue, the latter of which you may recall from this SCOTUS season's
CFPB case. The USG response is twofold:
- SEC penalties aren't what the seventh amendment addresses.
- Congress afforded enforcement discretion to the SEC and other agencies with administrative courts, this undermines their will.
I should caveat that here I am going off of reporting, I haven't dug into oral arguments. Though I won't pretend to understand "suits at common law" to which the seventh amendment applies,
in a general sense the judicial system seems like it should be a an appeal path afforded to any administrative law decision.
I find myself conflicted since
I've long been cautious of nigh-unavoidable mandatory binding arbitration agreements. Vox saw the same thing:
|
Vox |
Few figures in American history, however, have less credibility to speak about the importance of the right to a jury trial, as Gorsuch's very first major Supreme Court opinion was a direct attack on that right. In Epic Systems v. Lewis (2018), Gorsuch wrote for the Court's Republican majority that employers have a right to force their employees to sign away their right to sue them in any court at all - including courts that protect the right to a jury trial - and to shunt those cases into private arbitration.
Indeed, the Court's GOP-appointed majority has long been vocal advocates of forced arbitration, dismissing arguments that these privatized forums violate the Seventh Amendment, and often mangling the text of federal statutes to maximize employers' power to avoid jury trials.
|
I'm not sure the framers intended for the Bill of Rights to be something you had to surrender in order to gain employment, but it's as much the responsibility of Congress to protect against that situation as it is the responsibility of SCOTUS.
Impact
The consensus seems to be that
administrative law greatly increases the SEC's capacity to protect Americans from theft of the kind that Mr. Jarkesy perpetrated (for other examples, check my
watch list).
|
fastinserter |
Suddenly pushing all administrative justice on to the courts so everyone gets a trial for when they break every federal statute would be chaotic... at best.
|
Moving the SEC adjudication process to the courts could be chaotic and/or grind justice to a near-halt.
|
Vox |
The federal government employs nearly 2,000 administrative law judges, in addition to about 650 non-Article III judges who hear immigration cases. Meanwhile, there are fewer than 900 Article III judges authorized by law. So, if the United States suddenly loses its ability to bring cases in administrative forums, the entire federal system will lose the overwhelming majority of its capacity to adjudicate cases - forcing litigants to wait years before an Article III judge has the time to take up their case.
... both Gorsuch and Justice Brett Kavanaugh suggested drawing a line between cases where the government seeks to impose a "penalty" on a defendant, and cases about whether a particular individual is entitled to a federal benefit. That would require most SEC enforcement actions to be heard by an Article III court that can conduct a jury trial, but would also allow the Social Security Administration's more than 1,600 administrative law judges to continue to determine who is entitled to federal benefits.
|
The litigants "forced to wait years before an Article III judge is available" means
the SEC couldn't win repayment for Jarkesy's defrauded investors quickly or at all. Putting on the cynic's hat for a moment, this seems completely in line with what Justice Thomas's benefactors might want.
I haven't seen it in any articles so this probably isn't on the table, but wouldn't a ruling against the SEC reverse all of their judgments since the beginning of administrative courts?
Further listening
There was a great interview on
NPR about
how closely the current Supreme Court resembles its founding-era self (ahem, originalism) and how the so-called 'shadow docket' operates.




























































![[+]](https://www.chrisritchie.org/kilroy/archive/2023/10/hct_la.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/07/warrior.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2023/07/web.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2019/01/viscera_cleanup_mop.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2023/07/_CRR3746.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/02/far_cry_view_00.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2023/07/pool_resurface_concrete.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2020/09/da_bears.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2023/10/aeons_end_legacy.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2017/05/dying_light_stadium.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2023/10/clank_legacy_figurines.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2016/04/division_helo_00.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2023/07/pool_resurface_curing.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/11/deezer.jpg){kind=link}
{kind=link}