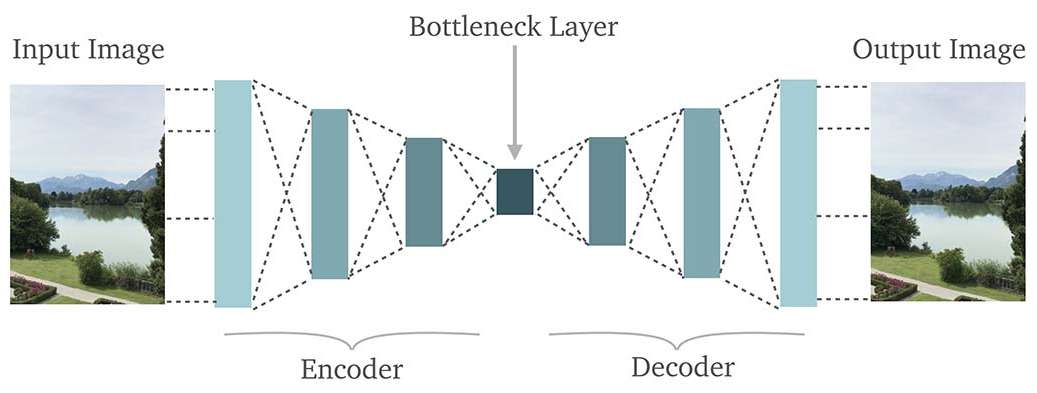
Autoencoders are primarily used to perform image denoising (and as ML examples). AE compression does not stand up to mathematical algorithms, but neural networks can learn graphical features and draw them into an image. An autoencoder can also generate/repair images by tweaking the 'latent space' which is basically the network's abstract idea of what is in the image.
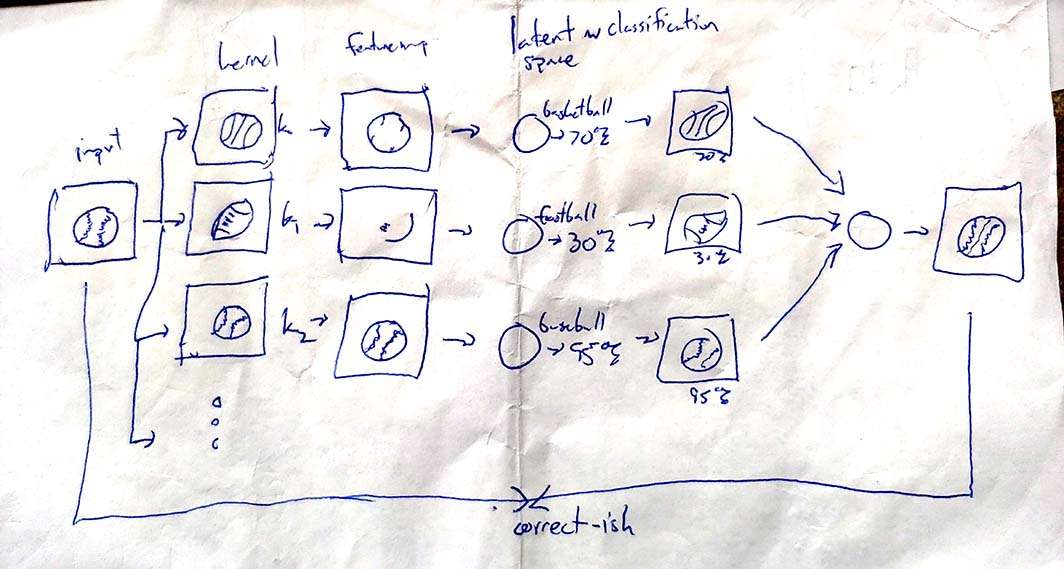
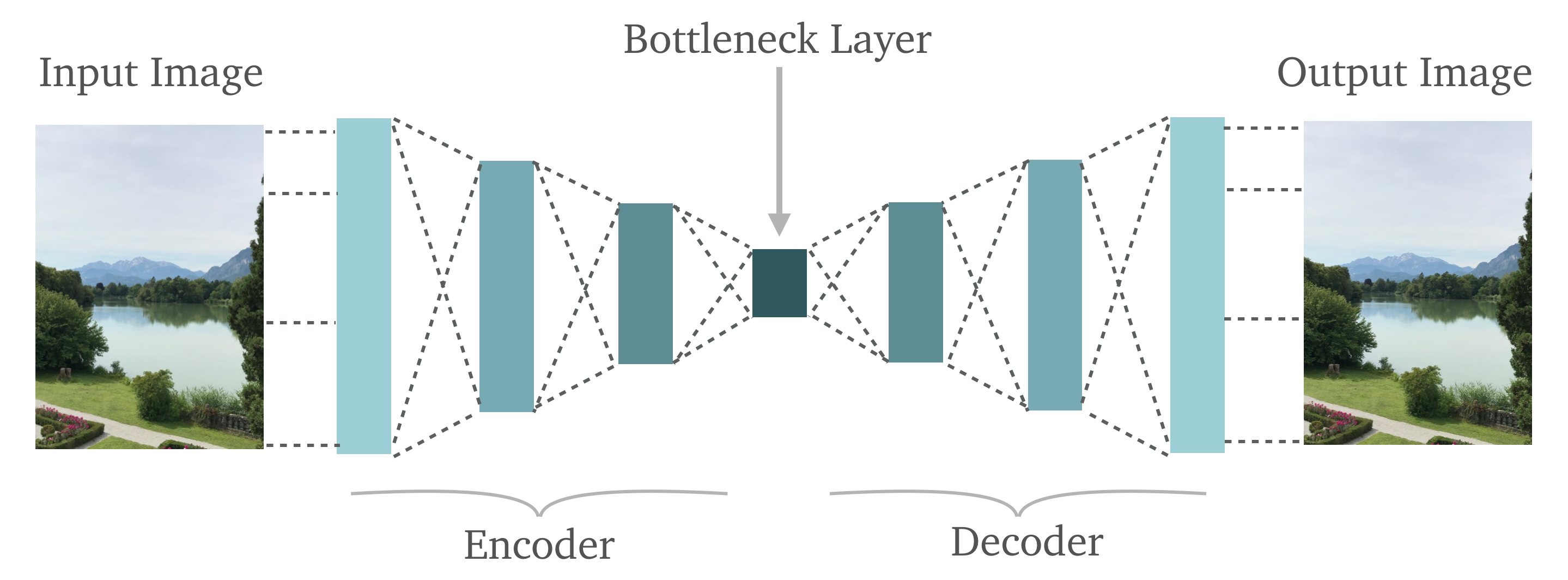
I tried to draw my best understanding of a convolutional autoencoder on a cocktail napkin (with oversimplifications described later). An autoencoder might learn what a type of ball looks like and use that information to redraw it, given partial or complete information. The latent layer amounts to a classification or set of classifications.
The encoding portion consists of convolutional 'kernels' (m-by-n filters) that get dragged over the image and produce a 'feature map' that is basically how the image is seen by the kernel's understanding of the world. Convolution is necessary to see features in a position-independent way.
The latent space reads all of these filters and decides what is in the image, kernels that don't recognize anything will not be as loud as ones that do. The decoder then takes this information and redraws the image using transpose convolution (the inverse of the encoding portion). By comparing the input and output, the network can learn without classification or additional supervision.
The above drawing uses kernels that see an entire ball. In practice, they only recognize certain portions of each object. By having many layers (left to right), the interpretation of the image gets more abstract.
Troubleshooting
I don't quite remember where I left off with my previous attempt, but in giving it another go, I hit something that felt familiar: the network would produce a flat gray output image that seemed to be shooting the median pixel value for all of the training data. So I was starting from scratch.
I don't think using rms loss was my issue; this is a pretty standard measure of error for networks that produce images. Learning method matters, so I switched between adagrad and rms prop.
Most autoencoder examples use images no larger than ~120 pixels per side. This makes sense for a lot of applications (e.g. the standard MNIST number recognizer) and certainly cuts down on training time (especially relevant since most available code is sample code). My original goal was a bit higher: 512 squares with larger convolutional kernels. I was aiming to have a network with 40k-1M weights, and perhaps this simply isn't enough to handle such large input. Then again, the point of convolution is to be highly independent of input dimensions, so why would a 64x64 input be any worse than four 32x32s? Among other things, the answer is that each kernel produces a same-size feature map and that quicky eats up available memory.
Proceeding, for a time, with that image size naturally meant smaller training batches. I had hoped to address this simply by doing overnight runs, but after hours my output was still monotone gray and occasionally a checkerboard. I was expecting to see something resembling progress (e.g. blotchy noise) early on.
I pingponged between sample code. Everyone seems to do things a little different - except for the people who just copy and paste the official Keras example and call it their own. It really doesn't help that so many examples are hardwired to use existing models or input data. Swapping snippets isn't hard, it just takes time to get everything rewired for a given method of doing input/batching/display/normalization.
I eventually dialed it down to 32x32 so I could hasten the trial and error process. Previous attempts used a bunch of noise/dropout layers that are generally good practice, but I was concerned some of these might be cranked up too high. Certainly upon re-reading SpatialDropout2D, I realized that cutting an entire feature map from a layer with eight kernels might be a bit heavy-handed. I had quite a few batch normalizers in there as well.
I wasn't sure about the latent layer so I removed that, having seen a number of examples that simply went from convolution to transpose convolution.
What I really noodled on was the output layer(s). The decoder portion of the network is a bunch of transpose convolutional layers that take abstract information and redraw the features that were abstractized by the encoder. So as the decoder traces out a bunch of feature maps from latent space (and maybe enlarges it), you'll end up with a bunch of semi-images that must be recombined. This seems like a crucial step and all of the examples I saw seemed to have a different approach but not much in the way of an explanation of how.
A common approach is an n-channel dense or convolutional layer that takes all the feature maps (width, height, channels, kernels) and spits out an image. This makes sense - the layer uses each kernel's output to decide whether or not to fire. I have however, been wary of the model summaries that show dense layers having not a lot of weights, particularly when troubleshooting an autoencoder that produces no detail.
I found another implementation that used a single-kernel (per channel) 3x3 convolutional layer. While this makes sense for output shape, it seems like you're producing an output image by dragging a 3x3 conv box across a bunch of feature maps. This feels like a massive dumbing down of the elaborately-constructed data.
What I settled on for the back end of the transpose convolutional block was a dense layer with a lot of units. Typically you'll see units = 3 for RGB and 1 for monochrome, since the dimensionality of the output space is a tensor or whatever. I'm sure this is the right approach for many cases and takes advantage of the magic of a dense (weight-shared, not fully-connected) layer, but I was worried about bottlenecks and concerned by the number of parameters associated with the dense(3) layer.
More precisely, I used dense(units=a lot, relu) followed by dense(channels, linear). The first, large, relu layer was meant to combine all of the transpose convolutional feature maps in a manner that allowed a large number of knobs to be turned by the magic of neuroscience, training, and cuda. Then an output-size final layer to decide how to interpret the mess of activations before it. Linear activation is scary since it's combining a bunch of inputs, but makes sense for a 0-255 output.
Trying it out
I have a few data sets to choose from:
Twenty years of photos - unlabeled, large image size, variable subjects.
A few years of screencaps - labeled by game, hd resolution size, variable subjects and styles.
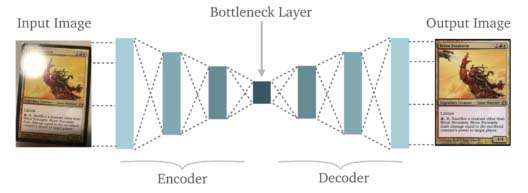
MTG card repo - small images but heavily labeled.
Open source data - boring.
Using my Java graphics library, I wrote an image sampler and set it upon my Horizon: Zero Dawn screencap directory to produce 1000ish 32x32 squares, it started noisy then got better and better:
After an hour or so with a batch size of 160, I was getting down into the 0.00x loss territory. In retrospect, this was despite the fact that my input/output training sets were being independently rotated/mirrored. Whoops. Regardless, output from these small pieces started looking like input, but neither really looked like anything since they were 1/2000th of an image.
So the next thing was to write a script to apply the autoencoder to an entire image, square-by-square. Not only would this reconstruct something that actually looked like a thing, but it'd be a good test of if the autoencoder was overfitting the training set. The output looked way better than a flat gray png.
The square-by-square application left obvious borders in the decoded tiles. This was likely because edges of each tile have less data than the middle portions. The simple solution was to modify the stitcher to crop the few boundary pixels and change the step size to remove the gaps. The right way to do this, however, is to have a 32x32 autoencoder only produce a 24x24 output, thereby saving on network size and computation.
Next steps
There are a few things to try next:
Implement the 32->24 network.
Re-introduce the latent layer.
Use more similar data. A random HZD screenshot is a fairly arbitrary set of features to be learned. Using like input, I could perhaps get better results.
Adding a post-decoding back end of convolutional layers might be a cheap way to produce sharper images. A better way may be using some existing work.
Other people's (neural) fails
My phone automatically tags images (thanks). Pretty much everything on it is a memebank (because using gif services is cheating). This has resulted in a few awesome fails. Apparently weapons look a lot like musical instruments and a heart looks like a fruit. Stormtroopers are basically mannequins - we all knew that anyway - and jazz addicts use their (jazz?) hands.
On this flip side, I could go for a sculpture of Christian Pulisic riding a dragon.
Fox is clearly using a deepfake merge of Donald Trump and Rudy Giuliani for its contributors. Nice try.
Perhaps I simply don't appreciate it, but it seems like some of these neural algorithms are pretty overhyped. We've already covered neural style transfer, though I kind of like that one. I ran the default example of Deep Dream; it's... a crappy kaleidoscope. And both kind of cheat by modifying the original image with an activated style layer - escaping the problems with generating a wholly new image and making the application of their algorithm extremely slow.
Tool
Lee scored some tickets to Tool earlier this month. It was a great show. They were strict about use of cellphones (which was kind of nice) until the encore. I grabbed a couple shots and then went back to enjoying it.
Gloomhaven
The Unnatural Ones' list of exploits keeps growing.
GBES
The Society explored the Miralani Makers District this month.
Thunderhawk Alements was standard Miramar fare, Serpentine Cider was - well - cider. I wasn't especially fond of most of the sakes at Setting Sun, but the place had style.
I happened upon a poster and wanted to know more, Katherina Michael's Amazon review.
Ben Adams is a surfer who finds himself responsible for neutralizing a terrorist threat. Well, obviously he?s not just any surfer? he?s a former FBI agent and also felon, who?s now retired and living a life of surfing and drinking beers on the beach. Trying to stay off the radar, he keeps to himself, with few ? if any ? friends, and a loyal dog. But the FBI has some leverage from his past, and has decided that his recklessness is a special talent, so has forced him to go undercover on an insane mission.
If he doesn?t comply, ISIS may get a critical nuclear weapon trigger and Ben would certainly go back to jail. But doing the job will involve high-speeds, high-stakes, and Ben?s own high-jinks thrown into the mix.
Late Apex is the third novel in Jeremy DeConcini?s Ben Adams trilogy. It?s an action-packed and fast paced page-turner in its own right ? you don?t need to have read the first two novels to dive right into this one ? with a rough and tumble hero you?ll love for his irreverence.
Thanks to his work as a Special Agent in the Department of Homeland Security, DeConcini?s experiences and personal political opinions permeate his plot and convince the reader that Late Apex?s storyline is truly plausible. All this to say? this highly enjoyable and suspenseful read seems realistic enough, even as we cringe at the American negligence.
Motorcycle, dog, fallout zone, racing phrase, surfer, FBI... it's like a perfect storm of awesome things. I don't think I'm going to read it though, it sounds like it's trying to be too awesome and can't possibly make it work.
Travel
What's better than an east coast trip during an impeachment trial?
You thought that was rhetorical. Answer: finding a goatse ͥ -inspired lamp.
This trip included stops at Dog Money brewery (great graphic design, not great beer), Vanish (good beer, great spot out in the boonies), the Potomac locks, and some other places. J and me finally vanquished Wotan thanks in small part to perfected builds and in large part to the DLC being scaled to player count.
Karakin
It's here, the new speed map. Complete with IEDs, rocket strikes, and...
... RPGs???
Also I perfected the genius tactic of spike-stripping a door. Then camping it. The spikes are mostly for entertainment.
When I said 'deadly' neurotoxin, the 'deadly' was in massive sarcasm quotes. I could take a bath in the stuff. Put it on cereal. Rub it right into my eyes. Honestly, it's not deadly at all. To me.
Here I present the photos from this decade that I like technically, aesthetically, or nostalgically. You may notice the post is at the beginning of the decade, I've chosen this as a convention so I can keep a running post for in-progress decades.
The month is March 2020. The Gateses and Ritchies have an ongoing game of Pandemic Legacy. We hear about this covid-19 thing and decided to meme about it.
Barrel, 'nuff said.
Another night surfing session with an improved strobe setup.
More telephoto surfing, but with LJ in the background.
Pretty F-18.
This day trip didn't go so well.
Epic day at Black's.
Neat mural.
Kind of reminds me of Metroid.
Cape Run, Turtle Team.
Danielle and the taco's first offroad trip.
A crystal clear, ice cold lake in Washington.
Diving board serves are a major draw of the League of Sport pool volleyball event.
The best place to watch the Blue Angels.
When can we start karting?
Even at 40' the kelp forests of Catalina Island can be pretty dark.
The F-22 has some neat moves.
Stay tuned, this one will update throughout the decade.
Cattle's xmas Steam gift this year was Pako - Car Chase Simulator. It had me pretty well captivated for my first two-hour session. I think I worked out a little bit of strategy:
Use a controller. This is mandatory.
Never drive in a straight line, a police car will always come from off camera to hit you.
ABB: always be boosting. The speed and drift are very useful in all but the tightest of areas.
And so find some tight, navigable areas to brake around, letting pursuers run into obstacles, then speed away before you get swarmed.
Use the rally car. It's fast and has predictable oversteer.
Fire your ammo off immediately. Most weapon types are too slow or narrow to actually save you from a collision, trying to line something up will likely result in a completely different death. Some weapon times (lasers, spiral ammo) will maybe take out far away pursuers and buy you a bit of time.
Consider saving the good items (force field, shrink, etc.) for an escape when you have no outs. This also means you'll avoid the negative items (poison, flashbang, shrink).
Anyway, it's a fun arcadey experience.
The music is neat, the action is fast.
It's like a streamlined version of GTA car chases without the long buildup or consequences for screwing up. And it feels a lot like Blast Corps.
Negative items kind of suck. The game isn't easy, but having a dice roll decide if you're going to get a run-ending poison is just cruel.
It's fun to hit the two-minute limit and start spraying bullets, but I feel there could be a longer ramp of difficulty/reward.
The power ups are numerous and fun (beachball!).
It's addictive, but I'm not sure about the replay value beyond a few challenges.
Where's my handbrake?
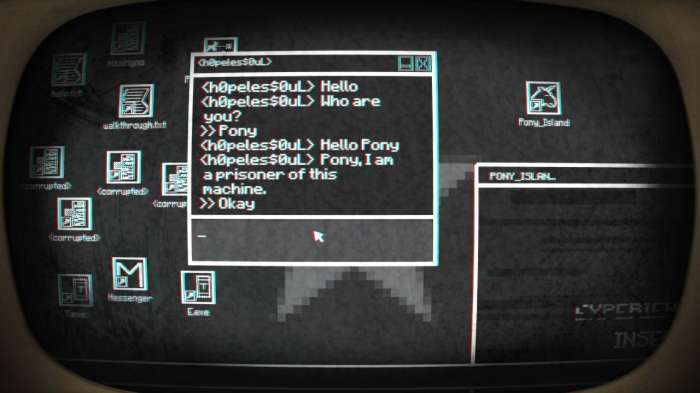
Pony Island
And Pokey got everyone Pony Island. I expected a rainbow sidescroller or maybe a weird rpg.
I won't spoil it, but the name is pretty misleading. It's a really cool puzzle game like Myst with a Lost (tv show) vibe - this is something you find out almost immediately so I promise I haven't spoiled it.
Oh yeah, and part of it is basically a debugger, so that's fun.
Post-Scriptum
Some of the PUBG crew bought in-development Post-Scriptum about a year ago. It was on the shelf for a while, but Cattle and I decided to give it another go. It doesn't seem to have changed much - it still has all of the complex, deliberate gameplay that is its hallmark. Of course this makes the game hard to play casually and it's hard to go deep into a game you're not sure you're going to continue playing.
I (calmly) ragequit the last session after 60 minutes, a dozen deaths, and zero enemies seen. Unless I'm missing something, it feels like the one sniper you're allowed to have per squad is just super OP. And if that's historically accurate, then it fits the game. But other than a few iconic scenes from the silver screen, I don't remember having seen or read about markmen being decisive tactical elements in WWII. Perhaps that has to do with the sheer numbers involved in actual battls vs 40/side Post-Scriptum.
So at the end of the day, all of the amazing graphics and team mechanics are - for me - defeated by the fact that as soon as you get near the front, you'll be shot long before you see an enemy infantrymen. PS is still(!) in (active?) development, but at this point if I want tactical MMOFPS action, I'll fire up Planetside, it has half the depth but infinitely more approachability.
PUBG
With increased stability and finally MMR (temporarily), we gone back to PUBG over the holidays and had a good time doing it.
Cattle and I had a very Silver League shootout. To narrate the above:
We got into Mil Base early (see driving video below) and were hanging out at the edge of the circle - we aren't cowards, I had no 5s for my SCAR.
We heard some dudes outside the house so we covered both doors.
Oops - the bathroom had a non-glass window, so some guy came out of the bathroom door and shot me in the face (non-lethally). But the far superior noob tube took him out with a well-placed panic shot between the legs.
I planned to flashbang the bathroom, but was on underhand throw and the other dude was already inside.
So my flashbang blinded both remaining players as I got knocked.
After a lot of blind firing, Cattle drops the other dude.
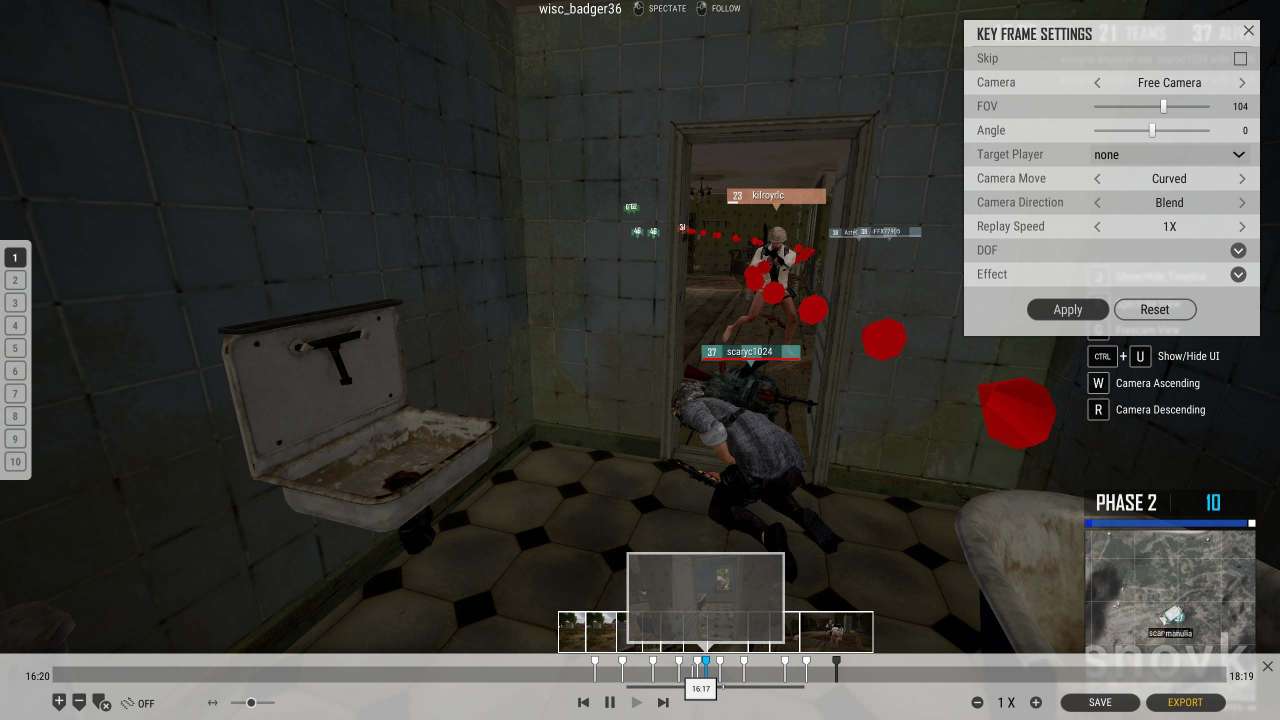
Anyway, Cattle requested a video, so it was a good time to try the updated (months ago) PUBG video editor.
Previously you could just watch replays and had to do a screen record, this actually has cameras and video output. That really opens up the editing options, where previously you needed a stationary camera or numerous tries to get a moving camera (with no pan).
The key frame settings are buggy, so you frequently have cut and retry key frames. It takes an hour or so to figure out how to work around the issues.
Export creates a strangely-encoded (Firefox hates it, Chrome plays it) webm with no mpeg or avi option. I never had sound on any of mine and found nothing when searching for solutions. I'm not sure if I have something wonky going on or if everyone just sets their videos to music. My workaround was to do a screen record and add the audio as a track for my webm converted to mp4. This, of course, means timing the audio start and not using slow mo: not fun.
The other major weakness is that you can't jump back in time. While doing so can be confusing, but if it's done right it can be really neat. If you're going to jump between perspectives, it's good to rewind a couple seconds so the viewer can track the camera change. And as can be vaguely derived from the video below, sometimes there are two cool paths to follow. I knew from memory that we had a neat buggy vs motorbike race to the island, but didn't realize there was a Kenny Powers-style jump from one of our adversaries. I could have generated two videos and cut them in, but I'd rather have multiple timelines and bounce back to the chase after watching that majestic bike jump.
The Hacienda Heist
The new meme strat is to drop into Hacienda to nab the gold camaro (mirado). After one incidend where I ran Cattle over, we decided it's best to have one person grab the car while someone else loots a cold warehouse on the outskirts. You still end up having to drive through a town where people are already looted up, so it's perilous. But meme strats aren't meant to be easy.
The old meme strat is to go to a Vikendi church and pray to RNGesus





















































![[+]](https://www.chrisritchie.org/kilroy/archive/2019/08/ror_meme.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/07/warrior.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2019/10/party.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2016/04/division_helo_00.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2019/12/solar_sc.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/02/far_cry_view_00.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2019/12/vr_sc.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/11/deezer.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2019/10/chicken_waffle.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2017/07/dying_light_mother.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2019/10/brewery.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/02/far_cry_items.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2019/10/risk_of_rain_allies.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2016/08/witches_lair.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}