Jon, J, and I watched the
Aeon Flux Rifftrax. Such great commentary for such a terrible movie. If only we'd had the time to also do
Over the Top.
So in
super-awesome news, Nelson, Murphy, and Corbett are coming to San Diego to do
Plan 9 From Outer Space live.
If you want in, let me know soon.
I was chatting with
Jon about the
application of neural networks to stock trading, which is basically a perfect example for explaining the science. It went something like a'this:
> Okay. You want to tell me more about this program since I don't read code?
Think if you had
three inputs to determine the price of GOOG tomorrow, all doing math by hand. One input is yesterday's price, another is Joe Expert's opinion, and the third is the number of internet subscribers on the planet.
A simple way to create a prediction would be to
assign a weight to each, maybe 90% to yesterday's price since the stock probably won't swing much in one day. Then 7% to Joe's prediction since he's pretty good but not perfect. Then 3% to internet subscribers, since more users means more clicks on Google links which means more revenue. (For the moment ignore how the weights compute to actual dollar values).
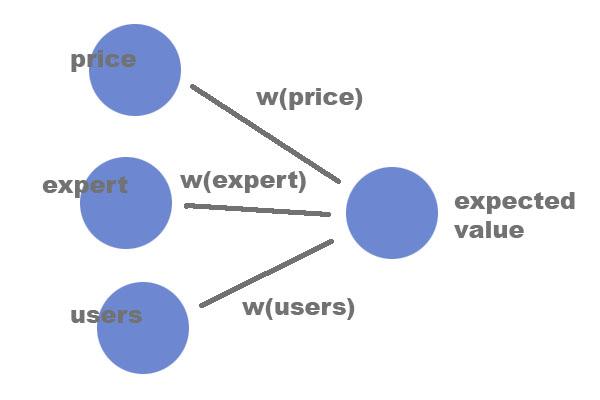
A simple neural network. The nodes on the left are inputs - that data for any given day. The node on the right is the output, its value is a combination of the lefthand values and their respective weightings. The means by which they are combined is application-dependent.
How do you know your weighting is good? Try
applying it to historical data, of course. See if this mix of weights worked on April 5 2008. How about August 12-16 2007? Maybe you find the actual result is coming closer to what Joe Expert predicted at the time, rather than the previous day's price, so you decide to up his weight to 15%.
It's a lot of work, you're talking about divying 100% among three factors, and determining how accurate each combination is for n days of data.
It's a tough problem, but buy using fast computers and the beauty of random data sampling, it can be done.
And there's no cure-all formula; Joe Expert
isn't 7% right or 15% right all the time. Sometimes you want to value his opinion more. Sometimes less. If the stock has been flat recently, you probably want to value the previous day's number more. If it's jumping around Joe probably knows they're about to release Google _______ and it's better to listen to him.
To handle these complexities, neural networks add a second layer of weighting so that
each input is weighted against every other input, then these products are, in turn, weighted to produce the final outcome. It's somewhat magical, but basically you're letting each factor interact with every other factor to determine the best set of weights at any given time. That allows it to sometimes value Joe's opinion and sometimes not, depending on how right he's been in the past, under similar circumstances.
An archetypal three-input neural network. Each line assigns a unique weight to the value on the left and propagates it to the node on the right.
If applying your 90%/7%/3% distribution to historical data seemed like a lot of work, this kind of thing would keep you busy forever. But don't worry, it would keep a computer busy forever too. So human intelligence has to give it a leg up:
A.
Tell the network what factors to consider; historical price, number of internet users, MSFT price, etc. It will find the best weight for each; if you were to also feed it the price of tea in China, the corresponding weights would quickly drop to zero.
B.
Tell the network how to know it's getting close to the right answer (the correlation between how accurate it is and how you adjust the weights for the next try).
It won't be reliably accurate to a cent or even a dollar, since the problem domain is insanely complex (thus everyone is not a billionaire). Luckily the end result is reduced to buy/sell/hold so it doesn't have to be perfect to be useful.
I wrote a very simple network to predict GOOG share price based on the last year of trading. Instead of three input nodes there are thirty, each corresponding to the stock price on that prior day. After naively jiggling the weights around and keeping track of the best set, I ran the algorithm on the training data.
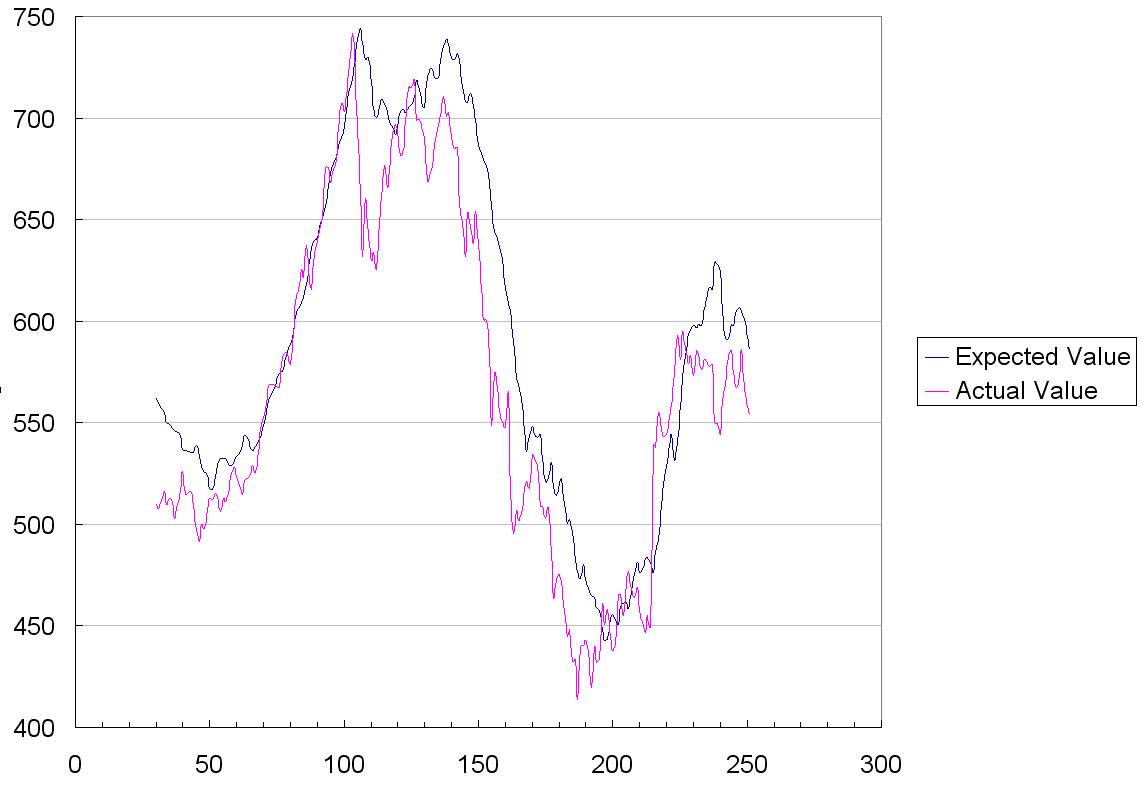
This is basically a measure of
how well the network remembers the information it was trained on. If it trained forever it could exactly reproduce the training data, but that's no fun.
Whether or not the algorithm can be used to predict future share price is depends on a few things. Neural networks are
especially good at recognizing patterns amid piles of unevaluated data. So it will be very strong when history repeats - even if very subtly. But a great supplement would be the relations it can find between other data (indexes, competing stocks, oil prices) as well as evaluating market predictions.
Neural network weights. Each value corresponds to the weight given to a particular day prior to the day that is being predicted.
As an aside, here is the worst Scrabble board ever (thanks Jon):
Naturally I will be indulging my curiosity as to the effectiveness of a good
stock market prediction network. It would be a shame not to put money where my mouth is.
I think the greatest opportunity to
improve the algorithm is to provide as
many reasonable prediction inputs as possible. The network will be good at analyzing historical data, but it will be great at merging this with informed opinions. After all, share value is as dependent on the present and future as it is on the past.
Finding sources for predictive information is no easy task. Most estimates are quarterly, far too low in granularity.
One concept that has gained widespread public attention is the
prediction market. The idea is that the informed opinion will prevail, and it's being applied most notably to the upcoming elections.
Prediction markets use currency, conveniently so does the stock exchange. Prediction markets apply economics and Darwinism to solve complex problems, neural network weight resolution is not much different.
So it follows that I could enlist a number of investors (using simulated money, at first) and
query each for a market prediction. These values would be used as inputs to the neural network and, with many other factors, determine the predicted share values. Each day the network would retrain itself and add weight to the more accurate voices.
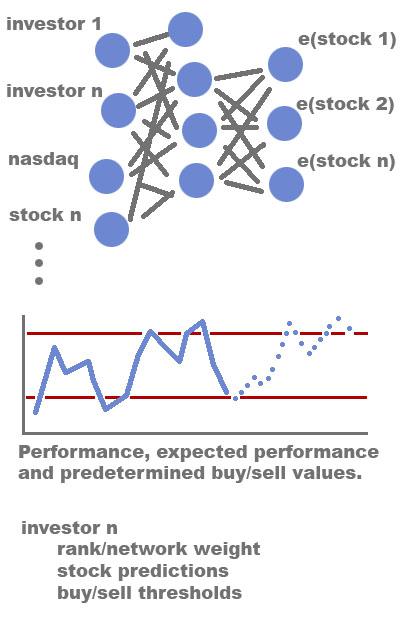
The three components of the algorithm: the network with investors as inputs, the short and long term stock value mapped to buy/hold/sell transactions, and the investor attributes.
Each investor would be
driven to produce accurate estimates as the collective account balance would hinge on their prediction. Moreover, if the quarterly gains were distributed based on each investor's prediction performance, the highly dedicated would be rewarded.
This model should
easily overcome the best case scenario of a single informed investor. Not only does it weigh and balance more factors than a human can individually process, but it sorts out bias toward or against particular stocks.