A little while back I ran into this Reddit post about using neural networks to redraw an image in an iconic art style. Okay, so, a computationally-intensive Instagram filter. Not really my thing but at the same time kind of cool. As it turns out, this dude implemented the thing using a Java deep learning library called DL4J. So a cheesy graphics tool as a way to get acquainted with a neural framework, why not?
DL4J
Alright, well, let's download this DL4J project and see how it goes.
"We recommend you use Maven and IntelliJ."
Git and Eclipse are just fine thank you. Let me just grab the zip and follow the blog you linked for instructions. ... Huh, failed on a JavaCPP dependency that leads to unsolved Q&A threads about dll hell. Nope. Not worth it.
Maybe the Maven recommendation is worth a try. So I downloaded it, did a mvn checkout and build clean. It took a few hours of troubleshooting various environment variables and getting the right JDK/JRE (needed 1.8 because examples use lambda). But eventually the clean build produced a .jar. It was kind of cool that Maven downloaded needed packages from the internet, but it's also frightening to have little introspection into the process.
Okay let's run some examples in Eclipse. Eclipse > Import Maven project. Wait, 'Run' is disabled. Google... I have to set up some lifecycle milestone CM crap to actually build. Great. And it still doesn't work. Amazon says I can create a shaded jar and then postprocess that to a runnable jar.
How about I create a new Eclipse project with the same Maven dependencies as the DL4J. Hmmm, looks like my pom.xml can either be runnable natively or have dependencies. Not both. Ugh. Maven, hi, okay so I get the awesomeness of continuous integration in the enterprise, but I just want to build and run. I don't want this.
Okay so if you add this to your pom.xml, you can run in Eclipse. "Unrecognized codehaus.mojo blah blah blah." Rage.
You know what, I have a jar. It should be able to run standalone (dll hell notwithstanding). Let me create a new project, import the mvn built jar, and see if I can import NeuronFactorySingletonFactoryListener.
Success. Okay, let's copy an example or the Schrum/Ramo code.
Right, so, GPUs are great for neural networks. And awesomely it seems like DL4J more-or-less has a switch you can flip to have the ComputationalGraph supertype use that sweet nvidia action. Somebody prints this at the beginning of each run:
Loaded [CpuBackend] backend
Number of threads used for NativeOps: 6
Number of threads used for BLAS: 6
Backend used: [CPU]; OS: [Windows 7]
Cores: [12]; Memory: [3.5GB];
Blas vendor: [OPENBLAS]
With some searching I found that if I go back and build DL4J from mvn with a pom flag switched, it'll build for GPU usage. And it did - the backend switched to GPU - however I ran into that JavaCPP error once again. It makes sense, you'd need C++ adaptation to run on the graphics card. But I wasn't able to sort this out before. The DL4J GPU stack is, unavoidably, a pain in the ass. It's some sort of combination of:
nvidia | cuda | javacpp | openblas | java | nd4j | dl4j
So Maven makes sense, but provides neither a shortest-path to Hello World nor a comprehensive solution. And, well, the lifecycle/pom overhead is too great for coding between dinner and bedtime.
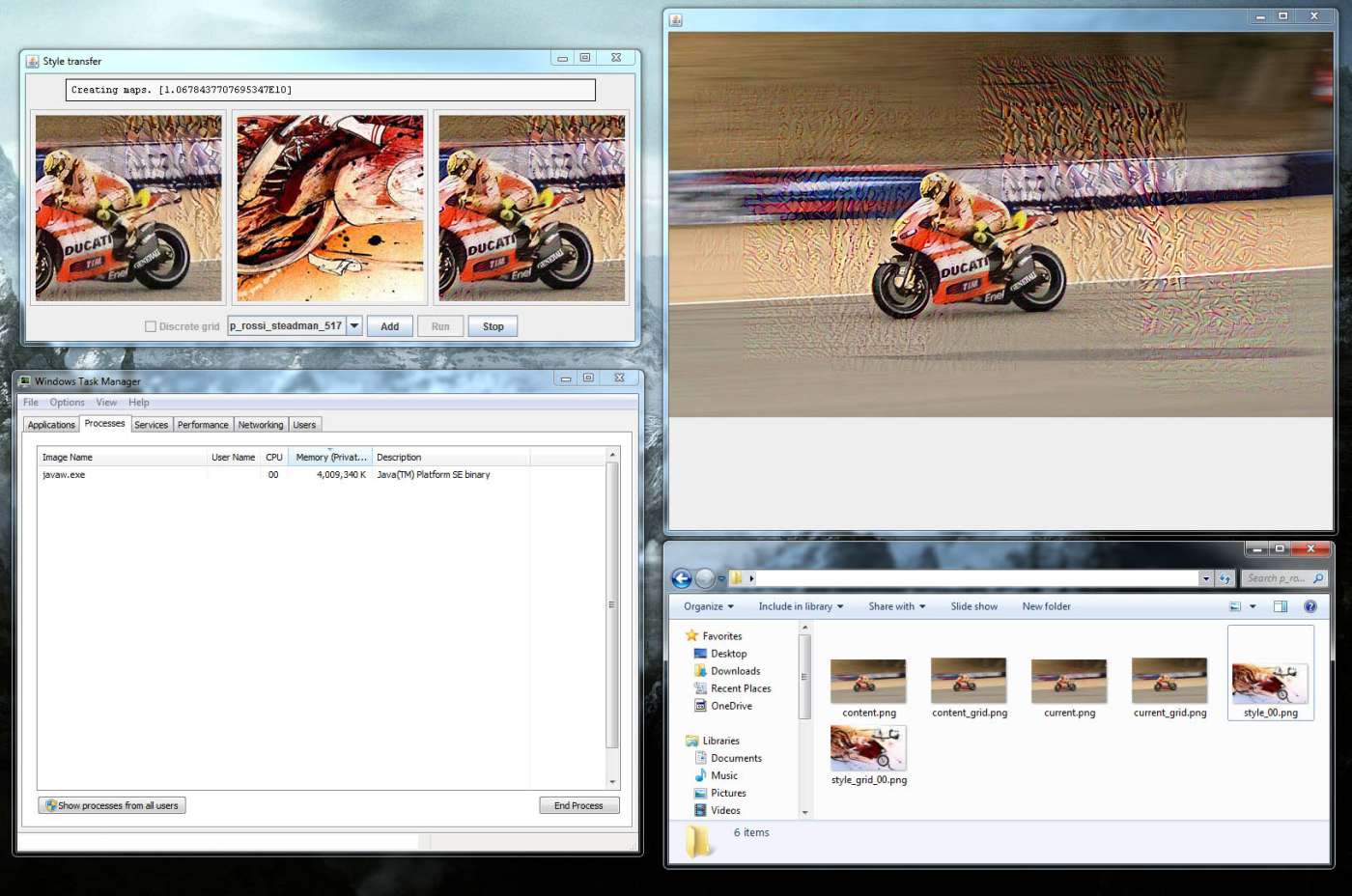
Style transfer
I moved on to the style transfer example.
Usually, to get decent results, you need to run a minimum of 500 iterations, but 1,000 is often recommended, while 5,000 iteration produces really high-quality images. Anyway, expect to let the algorithm run for a couple of hours (three to four) for 1,000 iterations.
I tried a Ducati with a Tintin cartoon for ~400 iterations. It looked interesting, and added some cell shading, but didn't look much like an Herge drawing.
With some reading and tweaking, I've figured out a few things.
The algorithm uses VGG16, a pretrained network used to classify images. That is, the normal output is 1000 values that decode to say "you've shown me a picture of a taco". This seems good in a way, as the network has some implicit knowledge of objects (in addition to simply having well-distributed weights). On the other hand, there's a lot of network that isn't used (afaik ͥ ), that is, the content layer is nine removed from the output layer. I think we backprop just from the content layer, but it'd be great to trim the unused memory.
The procedure - if I understand it correctly - is a bit different from an ordinary neural network. Traditionally, you feed input and based on the difference between the output and a ground truth, you train/modify the network.
For this algorithm, the network never changes (the code never calls fit() or touches weights). It simply feeds both images into the static network and then, using the error propagated from the style (abstract) and content (concrete) layers, modifies the original image. This process is iterated upon until the error is reduces and the image sufficiently matches the content and style inputs.
So I don't know of any way to make this a convolutional network - you seem to be stuck at the 224x224 input matrix. Of course, you can break up larger input images and reattach, but as the code author has indicated, this means twelve hour runs on a cpu. And that's the problem with the algorithm using a static network - you start from scratch each time.
Alternatively, you could select random patches of image to work on with the expectation that the style will converge eventually.
I tried doing rotation and mirroring on the style image since, in most cases, the art style is direction-agnostic. It seemed to result in a general improvement, if sometimes subtle.
Computer vision is pretty cool. It can take a picture of paintball, a picture of Metal Slug, and make it look like a badass video game - even putting explosions where they make sense.
Moving beyond campy filters
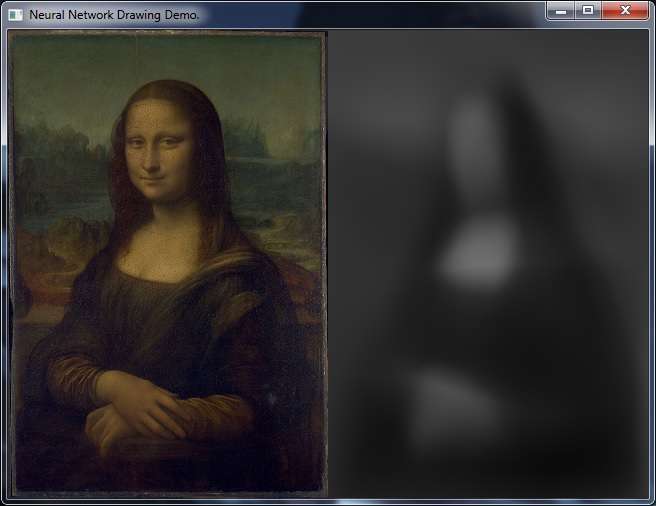
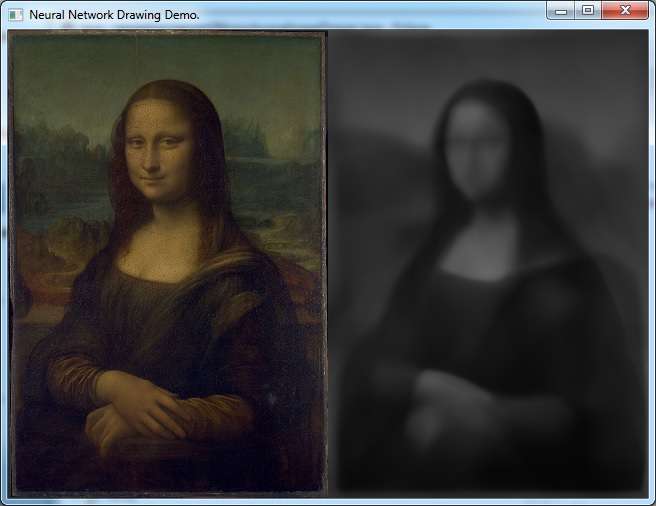
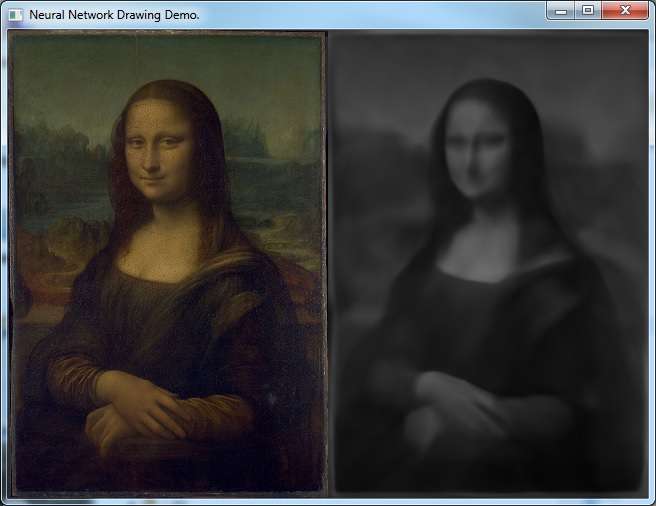
One of the examples trains a network to draw the Mona Lisa. (x, y) -> network -> rgb so maybe not the most efficient implementation, but straightfoward.
I tweaked it a bit to go monochrome rather than rgb. It takes some time to run, though.
Ski vid
Jon finished moving and editing the footage from Park City.
Atl
There was also a trip to a rainy, windy Atlanta. Not a ton to say about it, but Ri Ra was a great place to watch the football and Fox Bros bbq lived up to the hype.
More piracy
There's word of a sizeable content patch coming to Sea of Thieves.
Serpent and I stopped by this cool hideout for the first time a couple nights ago. It felt a little like Rebel Galaxy or The Division - here was this amazing place but not really any reason to be there. It's probably too hopeful to expect the patch to change the gameplay this much.
Still, the sea battles have been worth it. The lolbaters crew has improved its technique to where we stand a chance against most all newbs on the the water.
An implementation of the Burning Ship fractal and some experiments in creating autoencoders. Changing the style layers in style transfer and combining the outputs into a composite image. Mass Effect 3 Leviathan and Omega DLCs.
Experimenting with Dall-e text inputs, moving a sandbox example offline, and troubleshooting jax/cuda.
Related / external
Risky click advisory: these links are produced algorithmically from a crawl of the subsurface web (and some select mainstream web). I haven't personally looked at them or checked them for quality, decency, or sanity. None of these links are promoted, sponsored, or affiliated with this site. For more information, see this post.
Introduces a browser-based sandbox for building, training, visualizing, and experimenting with neural networks. Includes background information on the tool, usage information, technical implementation details, and a collection of observations and findings from using it myself.
Want to learn about PyTorch? Of course you do. This tutorial covers PyTorch basics, creating a simple neural network, and applying it to classify handwritten digits.









































![[+]](https://www.chrisritchie.org/kilroy/archive/2018/03/monster_hunter_cannon_loading_sim.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/07/warrior.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2017/12/monster_hunter_beta_dragon.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2016/04/division_helo_00.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2018/01/horizon_thunderjaw.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/11/deezer.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2018/03/tool_storage.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2017/07/dying_light_mother.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2018/03/fallout_boardgame.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/12/nick_valentine_00.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2018/01/horizon_weapon_wheel.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/12/diamond_city_00.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2018/04/gamora_hoist.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/02/far_cry_view_00.jpg){kind=link}
{kind=link}