Last post had some funny Elons. Here's how I made them. Well,
here's how a machine learning model made them with me serving as quality control.
"Hey check this out"
A few months back,
Zac linked
this blog post about
the new AI hotness, Stable Diffusion. Having recently
upped my CUDA game, I decided to give this model a try.
Environment
This part is boring but contains highly-specific troubleshooting information, for casual consumption skip down to "a photograph of an astronaut riding a horse".
Video cards don't hot swap
|
|
|
Since I had Dall-e draw a 'neural graphics card', I asked Stable Diffusion to do the same. It probably needed more guidance. |
I can't remember the last time I
upgraded a video card without refreshing the rest of the system, but here I was yanking a 1060 and replacing it with a 3080. Windows was somewhat straightforward: remove hardware, uninstall nvidia tools, put in card, install. I didn't touch cuda, cudann, etc., so there may be some follow-up if and when I do ML in Windows.
For Ubuntu I just ripped and replaced the card, then tried to apt install the updated drivers. Alas, the installer
halted on discovering that the 'nvidia-drm' kernel module was still running. The fix I found:
-- Remove nvidia-drm --
control alt f3 # Kill xwin, log in as root.
systemctl isolate multi-user.target # Remove any concurrent users.
modprobe -r nvidia-drm # Remove the nvidia-drm module.
systemctl start graphical.target # Restart xwin.
The lands between RTX and Python
There's a lot of software between nvidia drivers and a PyTorch script. On my box, all of it remained from the 1060 era, so
I wasn't sure how they'd do with their underlying software (the graphics card driver) changing.
Updating PyTorch
was previously kind of a pain, so I tried to avoid it, alas:
NVIDIA GeForce RTX 3080 Ti with CUDA capability sm_86 is not compatible
with
the current PyTorch installation. The current PyTorch install supports
CUDA
capabilities sm_37 sm_50 sm_60 sm_70. If you want to use the NVIDIA
GeForce
RTX 3080 Ti GPU with PyTorch, please check the instructions at
https://pytorch.org/get-started/locally/
I was on cuda_11.5.r11.5 and my existing Torch install was for 10.2:
In : torch.__version__
Out: '1.12.1+cu102'
In : torch.cuda.get_arch_list()
Out: ['sm_37', 'sm_50', 'sm_60', 'sm_70']
Some github bug thread mentioned that
3080s were not supported on that verison of cuda. The nvidia
Getting Started Locally link told me to run:
pip3 install torch torchvision torchaudio
--extra-index-url https://download.pytorch.org/whl/cu115
That command only successfully installed torchaudio.
So I went back through the previous steps of checking
the available wheels and pointing pip to the right one.
torch-1.12.1+cu113-cp39-cp39-win_amd64.whl
torch-1.11.0+cu115-cp310-cp310-linux_x86_64.whl <--
torch-1.11.0+cu115-cp310-cp310-win_amd64.whl
torch-1.11.0+cu115-cp37-cp37m-linux_x86_64.whl
torch-1.11.0+cu115-cp37-cp37m-win_amd64.whl
torch-1.11.0+cu115-cp38-cp38-linux_x86_64.whl
torch-1.11.0+cu115-cp38-cp38-win_amd64.whl
Basically what Getting Started Locally said, but with the specific Torch versions:
pip3 install torch==1.11.0+cu115 torchvision torchaudio
--extra-index-url https://download.pytorch.org/whl/cu115
Voila:
In : import torch
In : torch.cuda.get_arch_list()
Out: ['sm_37', 'sm_50', 'sm_60', 'sm_70', 'sm_75', 'sm_80', 'sm_86']
And just to be sure, I checked that torch and cuda both were working:
In : import torch
In : x = torch.rand(5,3)
In : print(x)
tensor([[0.2007, 0.7051, 0.0065],
[0.6201, 0.0654, 0.0358],
[0.5384, 0.0370, 0.5332],
[0.1488, 0.7525, 0.6938],
[0.1375, 0.6065, 0.1435]])
In : torch.cuda.is_available()
Out: True
Pip
There wasn't a requirements.txt that I could find, so I also needed to get:
pip3 install opencv-python
pip3 install taming-transformers
Models and checkpoints
The readme said to run
the model(?) downloader script, it took several hours. Next I needed model checkpoints, available after creating an account on Hugging Face and symlinking one of the files in the specified directory.
Quantize.py
Finally, I ran the Hello World script:
python scripts/txt2img.py
--plms
--prompt "a photograph of an astronaut riding a horse"
No astronaut, only:
ImportError: cannot import name 'VectorQuantizer2' from
'taming.modules.vqvae.quantize' (~/.local/lib/python3.10/site-packages/
taming/
modules/vqvae/quantize.py)
From
this,
something in the Stable Diffusion stack uses a no-longer-supported library, but you can download
the right one and update the various Python packages manually.
Side quest: Spyder
I haven't done a ton of Python at home or work until recently. IDLE and emacs aren't super great for it, so
in searching for a proper IDE I came upon Spyder. It seems to hit the sweet spot of not being too invasive (Eclipse) while being helpful (autocomplete and robust syntax assistance). It's "a Python IDE for scientists" so -1 for being pretentious.
Sure, let's do more troubleshooting
Alas,
the Spyder version in apt is apparently really old and chokes on a recent installation of Qt/QtPy. Since there's no standalone Linux installer, the solutions are:
- Use Conda. No thank you.
- Roll back Qt and/or use Docker. Nahhhhh.
I elected to go with option three. The exception pointed me to Spyder's install.py where
the incompatible lines of code all seemed to be about scaling raster images. I don't expect to heavily use raster images in a Python IDE and probably have the screen real estate to accommodate full size ones, so I commented out these lines. I expected another wave of Qt exceptions when I fired 'er back up, but everything worked.
12gb is not enough, but it is enough
I tried the
txt2img.py script that's basically Stable Diffusion's Hello World:
RuntimeError: CUDA out of memory. Tried to allocate 1.50 GiB (GPU 0; 11.77
GiB total capacity; 8.62 GiB already allocated; 654.50 MiB free; 8.74 GiB
reserved in total by PyTorch) If reserved memory is >> allocated memory
try setting max_split_size_mb to avoid fragmentation. See documentation
for Memory Management and PYTORCH_CUDA_ALLOC_CONF
Was tripling my video memory not enough? The messages is a bit unclear, as was repeated on the torch forums:
 abhinavdhere
abhinavdhere |
I got "RuntimeError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 10.76 GiB total capacity; 9.76 GiB already allocated; 21.12 MiB free; 9.88 GiB reserved in total by PyTorch)"
I know that my GPU has a total memory of at least 10.76 GB, yet PyTorch is only reserving 9.88 GB.
In another instance, I got a CUDA out of memory error in middle of an epoch and it said "5.50 GiB reserved in total by PyTorch"
Why is it not making use of the available memory? How do I change this amount of memory reserved?
|
Running nvidia-smi told me that steady state gpu memory used was 340MiB / 12288MiB, so running this without a GUI wasn't going to make much difference.
|
Umais |
I have the exact same question. I can not seem to locate any documentation on how pytorch reserves memory and the general information regarding memory allocation seems pretty scant.
I'm also experiencing Cuda Out of Memory errors when only half my GPU memory is being utilised ("reserved").
|
Others seemed to experience the same thing (in 2020) and I'm not the only one who sees ambiguity in that memory math.
|
ptrblck |
Yes, [multiple processes having their own copy of the model] makes sense and indeed an unexpectedly large batch in one process might create this OOM issue. You could try to reduce the number of workers or somehow guard against these large batches and maybe process them sequentially?
|
Ptrblck was addressing an issue with parallel processes sharing the GPU, but this was conceptually the same problem as mine.
When I dialed down the txt2img batch size or output dimensions, I stopped hitting the OOM exception. Deep learning model sizes explode when you increase image height and width; all of those highly-connected nodes must connect to exponentially more peers. In my limited experience, batch size (number of images you feed in at a time) only scales memory usage by a multiple of the input/output dimensions. Maybe Stable Diffusion handles batching differently. According to
this thread there may be some platform-layer memory management issues that could be resolved with additional updating.
An aside
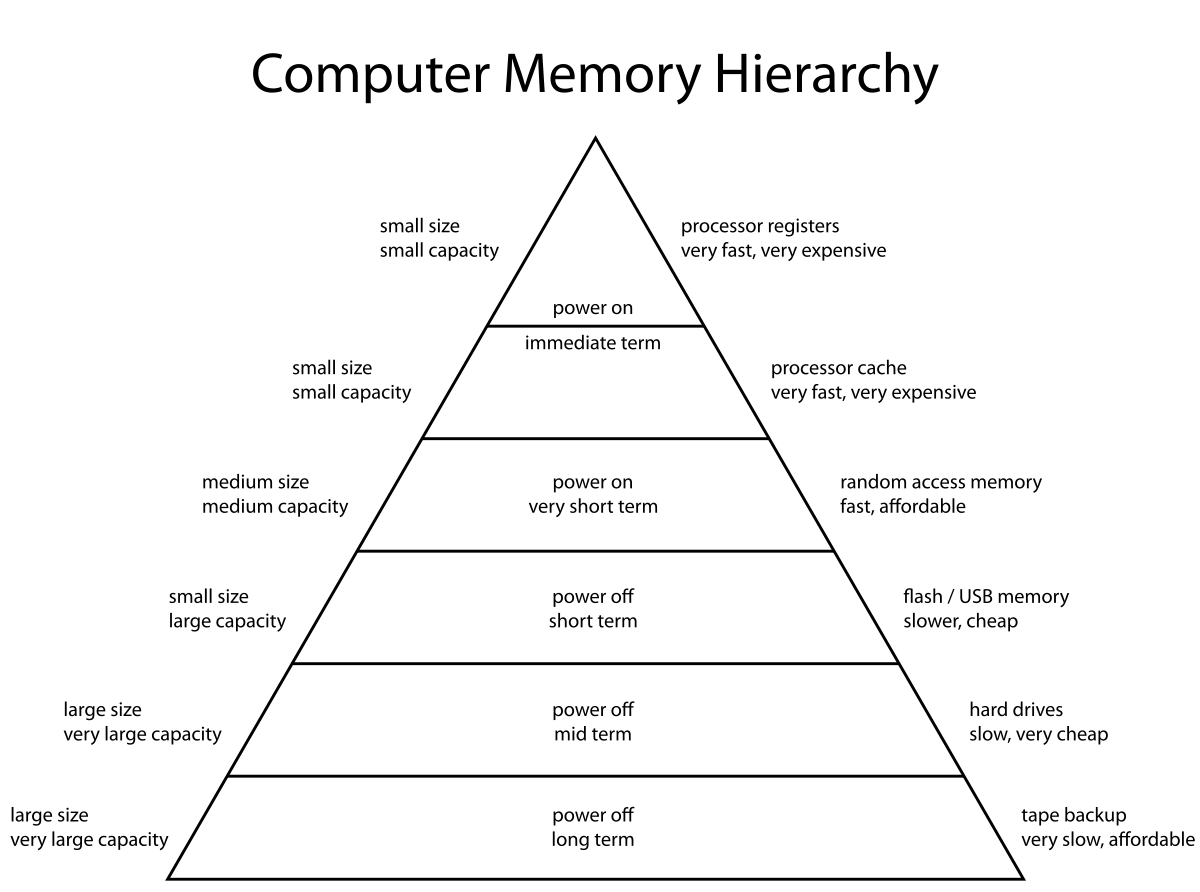
It's perhaps worth noting that this exposes a major shortcoming of ML platforms, they don't leverage the lower half of the memory pyramid.
Hardware-accelerated machine learning (at the consumer level) runs everything out of GPU memory,
this sets a fairly rigid boundary on problem size. If these platforms could wisely page out to computer main memory and virtual memory, that 12gb or even 48gb ceiling wouldn't be so hard.
It would be a little less challenging to support parallelism - connect identical 4090s and treat them a two processing cores with a single blob of mutually-accessible memory (mildly impacted by bus throughput). From the desktop machine learning enthusiast perspective, it means I could spend a paltry $1000 to double my model capacity. Alas, this
doesn't seem to be supported.
And so the only way to throw money at the problem is to
move from a $1000 gamer graphics card to a $10,000 48GB data center card. Or, of course, buy time at one such data center.
Models like Dall-e and Stable Diffusion have text interpretation components, graphics inference components, and generative components. I haven't peeled back the layers to know how separable these models are, but another theoretical solution is to partition the models under the hood. This requires that each step of the process be separable and would incur a performance hit of unloading/loading between stages of the pipeline.
Hello World
After all that I was able to run the Hello World script from
the docs:
python scripts/txt2img.py --plms
--prompt "a photograph of an astronaut riding a horse"
Well, deep learning is very sensitive to parameters so let's count successful execution as a win and try the other application of Stable Diffusion, img2img.
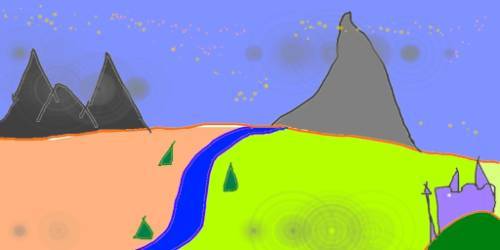
The input is an mspaint-tier drawing of a mountain and river.
Combining that input image with a text prompt should produce something like this:
python scripts/img2img.py '
--prompt "A fantasy landscape, trending on artstation"
--init-img input.png
--strength 0.8
My results weren't quite as refined, but certainly in the ballpark:
Variations and dimensions
txt2img
I ran the equestrinaut example with the default batch size (6) and had to dial down the output dimensions to not OOM my GPU.
Spamming nvidia-smi, I saw a peak usage of about 9gb:
python scripts/txt2img.py
--prompt "a photograph of an astronaut riding a horse"
--plms
--H 256
--W 256
+--------------------------------------------------------------------------
-+
| Processes:
|
| GPU GI CI PID Type Process name GPU
Memory |
| ID ID Usage
|
|==========================================================================
=|
| 0 N/A N/A 2106 G xwin
160MiB |
| 0 N/A N/A 2336 G xwin
36MiB |
| 0 N/A N/A 4618 G browser
142MiB |
| 0 N/A N/A 9537 C python
8849MiB |
+--------------------------------------------------------------------------
-+
I tried 512x448 and 512x324, both exceeded my 12gb video memory. I should note that these runs were done before the batch size fix discussed above (for topicality), these dimensions would probably work with a small batch.
I switched up the prompt and found that 448x256 worked:
python scripts/txt2img.py
--prompt "a computer rendering of a sportbike motorcycle"
--plms
--H 256
--W 448
Rigid airships
looked cool with Dall-e, so let's try:
python scripts/txt2img.py
--prompt "a zeppelin crossing the desert in the style of ralph
steadman"
--plms
--H 256
--W 512
+--------------------------------------------------------------------------
-+
| Processes:
|
| GPU GI CI PID Type Process name GPU
Memory |
| ID ID Usage
|
|==========================================================================
=|
| ...
|
| 0 N/A N/A 5211 C python
9743MiB |
+--------------------------------------------------------------------------
-+
img2img
For img2img I tried to channel both Andy's Seattle and the serene landscape of the github example. A zeppelin floats above Florence. And let's do an oil painting rather than a photo or cgi render.
python scripts/img2img.py
--n_samples 1
--n_iter 1
--prompt "Oil painting of a zeppelin over Florence."
--ddim_steps 50
--scale 7
--strength 0.8
--init-img florence.png
+--------------------------------------------------------------------------
-+
| Processes:
|
| GPU GI CI PID Type Process name GPU
Memory |
| ID ID Usage
|
|==========================================================================
=|
| ...
|
| 0 N/A N/A 8005 C python
7709MiB |
+--------------------------------------------------------------------------
-+
My 3080 easily accommodated a 448x336 image, probably because I set the samples/iterations to one.
The first pass gave me a simple-but-coherent take on my input image as well as something, well, abstract.
Using the successful one for a second pass,
Stable Diffusion churned out a more colorful redraw as well as something significantly different. Alas, my zeppelin had turned into clouds.
A third pass on the more detailed image brought out some of the details:
Not quite Andy's postapocalypse/preinvasion Seattle, but it's a pretty good Hello World.
The lack of detail could be the oil painting directive, an ambiguous text prompt, or something else.
Hello World++
|
|
From the Stable Diffusion sub that also has this instructional. |
Style Transfer was a neat image-to-image application but compute-intensive and noisy.
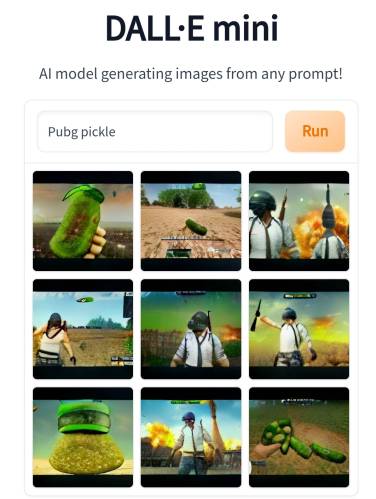
Dall-e Mini introduced (me to) a generative model using text inputs.
Stable Diffusion can do all of these. For serious digital artists, it can be part of a traditional Photoshop/Illustrator-heavy pipeline, e.g. the image above. For the more casual user, it can
'imagine' things from a text prompt or stylize a photo/drawing:
Some posts from this site with similar content.
(and some select mainstream web). I haven't personally looked at them or checked them for quality, decency, or sanity. None of these links are promoted, sponsored, or affiliated with this site. For more information, see
.



























![[+]](https://www.chrisritchie.org/kilroy/archive/2022/10/oktoberfest.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/07/warrior.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2022/05/carousel_ride.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2019/01/viscera_cleanup_mop.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2022/09/across_the_obelisk_martyrdom.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/02/far_cry_view_00.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2022/05/elden_ring_jarburg.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2017/05/dying_light_stadium.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2022/05/elden_ring_flamethrower.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2016/04/division_helo_00.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2022/06/leopard.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/11/deezer.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2022/05/elden_ring_erdtree_avatar.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2020/09/da_bears.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}