Topics:
- Google Search Console and site indexing.
- SEO from the outside looking in.
- Static website generation, some changes to how these words and pictures get here.
- Java parallelization, graphics code, and bugs.
Deindexed
I'm an indieweb wannabe and that means three things: I'm all about good content, I hate SEO, and I secretly need visibility and validation. Well, that doesn't exactly describe my sentiment either, but it's nice to see
my top search result for the last month was this Stable Diffusion setup issue:
importerror: cannot import name 'vectorquantizer2' from 'taming.modules.
vqvae.quantize'
Github bug threads aren't the easiest of reading so it made sense to summarize the fix for myself and anyone else trying to do the same thing. So it was frustrating when a bunch of people searched for it,
Google said, "I have an answer" and proceeded to link them to my blog landing page rather than the
specific post.
The #2 and #3 slots had to do with deckbuilders:
griftlands lick the goo
across the obelisk sylvie build
It's never not a rabbit hole
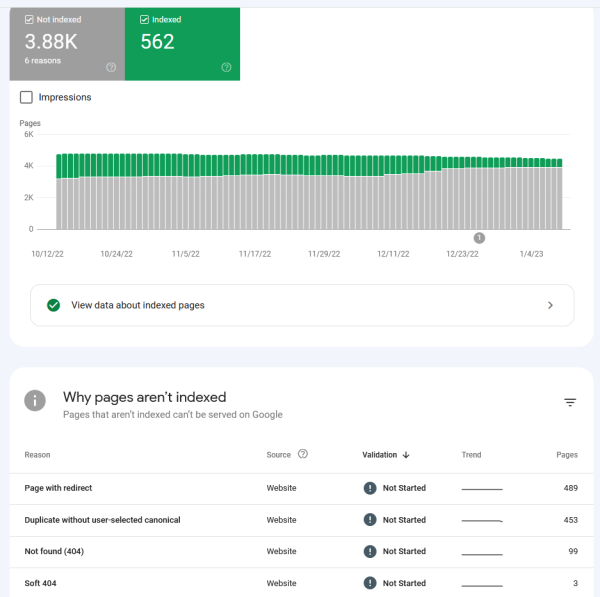
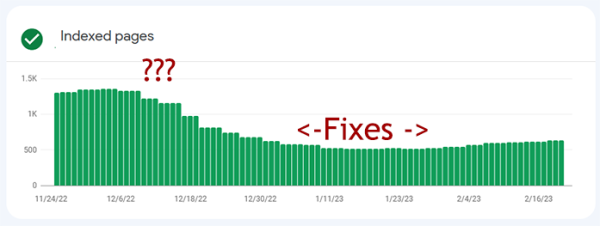
While scrutinizing my Search Console sitch I also found this:
|
|
|
Unindexed pages in gray, indexed in green. |
Other than tag culls and refactors, my site steadily increases in size. But
in December my footprint on the Googles took a sharp downturn.
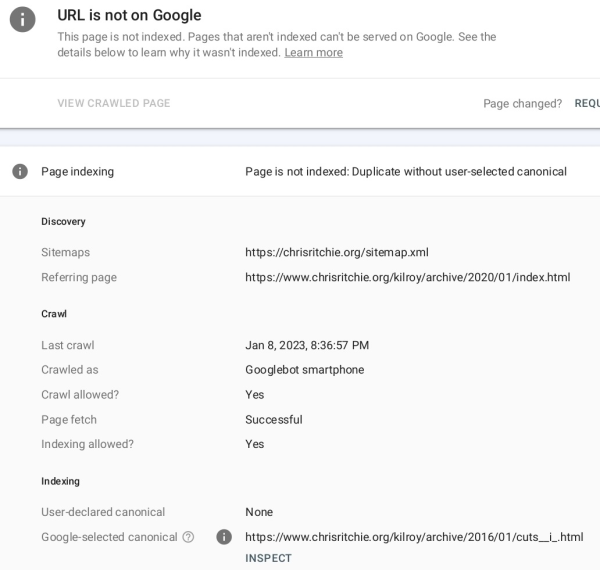
What the heck is "Duplicate without user-selected canonical"?
Answer, tldr: web sites duplicate a lot of content, so the internet longbeards decided
site developers should choose one golden url for each distinct chunk of data. That way, web crawlers can ignore the noncanonical stuff. Here's the tag:
link rel="canonical" href="https://www.chrisritchie.org/kilroy/archive/
2023/03/highlights.html"
My initial implementation just did "https://chrisritchie..." without the "www.". That caused some problems, including Google deciding the www. one was canonical but not indexing it. And in the realm of navigating the Search Console UI, this helped:

|
The "Duplicate, Google chose different canonical than user" status doesn't show which page Google chose instead. But you can find out which page Google decided to index using the URL Inspection tool.
|
Bringing my page headers up to 2011 standards
While I was on that faq, I
added a few more meta tags such that my header looks like this:
meta charset="UTF-8"
meta name="description" content="Three short clips from recent PUBG
matches."
meta name="keywords" content="lolbaters, battlegrounds, video, fps battle
royale, battle royale, pubg, video games"
link rel="canonical" href="https://www.chrisritchie.org/kilroy/archive/
2023/03/highlights.html"
meta name="viewport" content="width=1030, initial-scale=1.0"
link rel="stylesheet" type="text/css" href="../../../style.css"
link rel="shortcut icon" href="../../../res/favicon.ico"style type="text/
css" media="screen"/style
- I was already generating a description for RSS, so that was easy.
- For keywords I could just sample my post tags. Again, easy.
- The UTF-8 means that anything copypasted from an iphone or other devices that prefer extended characters instead of ', ", and - will show up as in the browser.
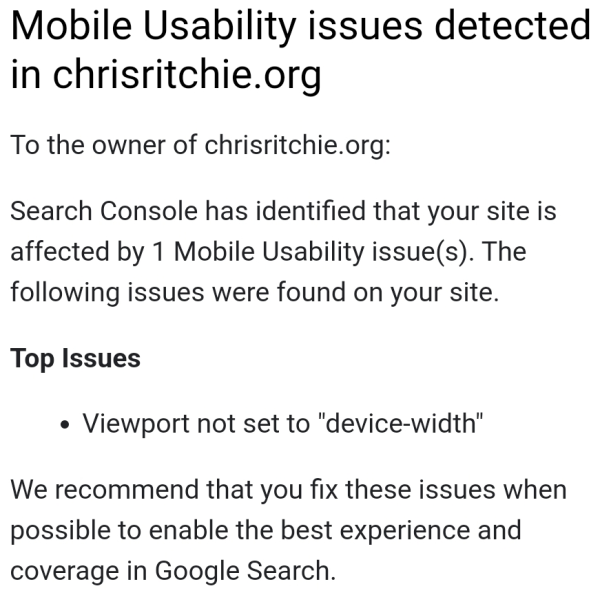
One more:
|
|
|
The beautiful thing about variables is that they can have different values rather than just one acceptable assignment. Yeah, mobile sites are trash and need to die, so I'm leaving this at exactly what my page was designed for. |
Did it work?
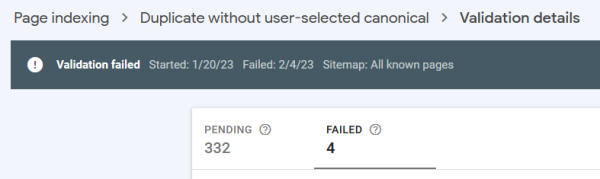
The neat thing is, you can do a batch re-run on the errors Google finds. The not-so-neat thing is that
Search Console just abandons the effort if it finds a few pages with issues. Not pouring resources into validating something that wasn't fixed makes sense, except when the chunk of urls to revalidate includes a bunch of moved or removed content. I assume there's a way to blacklist that stuff, but it'd be nicer if it just skipped the 404s and moved them to a different error category (where the lone "Validate Fix" button would be accompanied by a trash button). Considering how much churn web sites have, I'm sure there's a way to do it I just haven't looked too hard.
I guess in December Google changed something and began rejecting my pages left and right. Since then it's been a slow climb back.
Slow climb
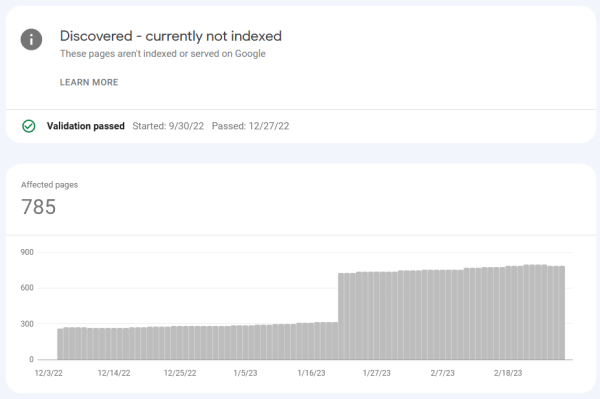
Around the time that I started labeling my canonical pages, Search Console showed a big spike in Discovered/Unindexed pages for the canonical urls. I guess
the canonical pages weren't reindexed in the validation phase, they're just sitting in the deep backlog.
SEO
 Gagachicken Gagachicken |
Two SEO experts walk into a bar, bars, nightclub, pubs, tavern, beer, alcohol, drinks, alcoholic beverages, bars in my area, places to drink.
|
I hadn't seen the meta head tags before, though I certainly never looked. I also don't even try checking out the html for professional/SEOed web sites, they're not meant to be read. But since I was already looking at Search Console and easy-win meta tags,
I popped over to /r/seo to see what people do.
The sub felt like one of the many also-ran meme stock forums (AMC, Blackberry, Hertz, Nokia, Clover). Everyone was focused on scraping out a few more clicks to make those monetization tendies. The posts and top comments had Secrets to Business Success conference vibes - "my company turns nobodies into tycoons, here's a taste, PM me to find out more!" This guy was actually pretty alright in the comments but his title gets the point across:
 malchik23 malchik23 |
SEO is easy. The EXACT process we use to scale our clients' SEO from 0 to 200k monthly traffic and beyond
|
Despite the sub being business-oriented,
there were a few interesting technical tidbits to someone familiar with the technology but not the standards.
Posts on /r/seo had the basics like "have a sitemap and robots file". Then there was "don't have 30MB images and use that neat new webp format". The more involved site audit techniques advised
scrutinizing words and phrasings to closely align with targets searches. Yuck.
And finally, linkbacks. The /r/seo contributors talked about basically having an 80s business guy rolodex of sites that'll link to their content without getting both blacklisted. And that's part of why
Google search sucks.
 Rob Rob |
The web was a mistake let's go back to the internet.
|
Eternal September and such.
Development
Since internetting is a hobby and I'm not a web developer,
I've slowly adopted normal web site stuff. For example:
I did a favicon
Landing pages/index pages
https://chrisritchie.org/posts.html ->
https://chrisritchie.org/kilroy/all/index.html
The post index page shows
title, description, and tags form all 600ish posts here. Since pure text walls aren't fun, the page is seasoned with a sampling of lead images that changes every time I generate the page.
https://chrisritchie.org/kilroy/tags/index.html
I brought tags over from Blogger, but never properly indexed or aggregated them. It was easy enough to give /tags
an index.html showing a randomized dump of all the tags.
https://chrisritchie.org/games.html ->
https://chrisritchie.org/kilroy/games/index.html
In December
I talked about moving video games from being representated as tags to being its own data type.
Each game has a page and there's now an index page with all of them. The game title still appears in the tag section of each post, but the link takes you to the game page.
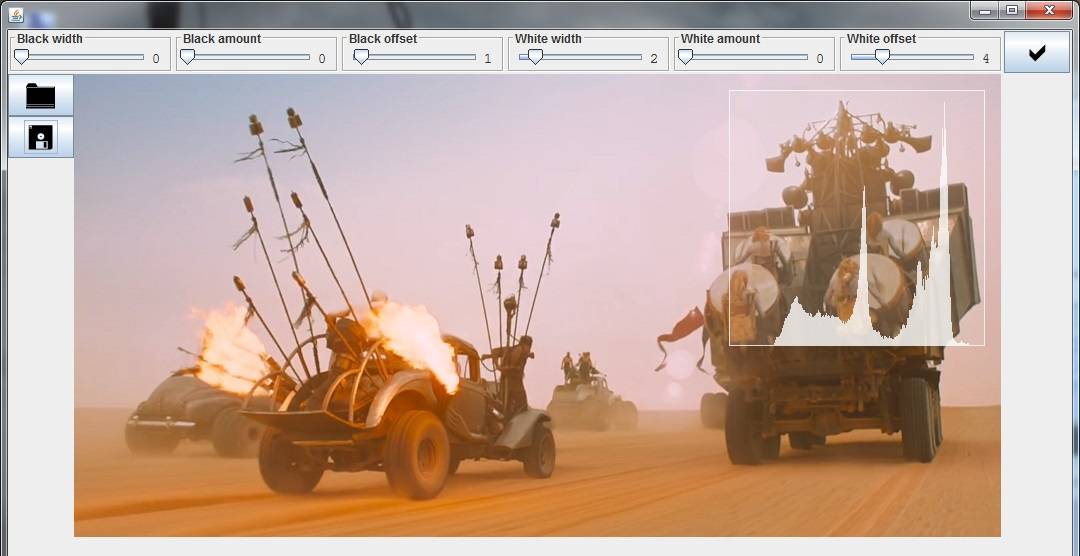
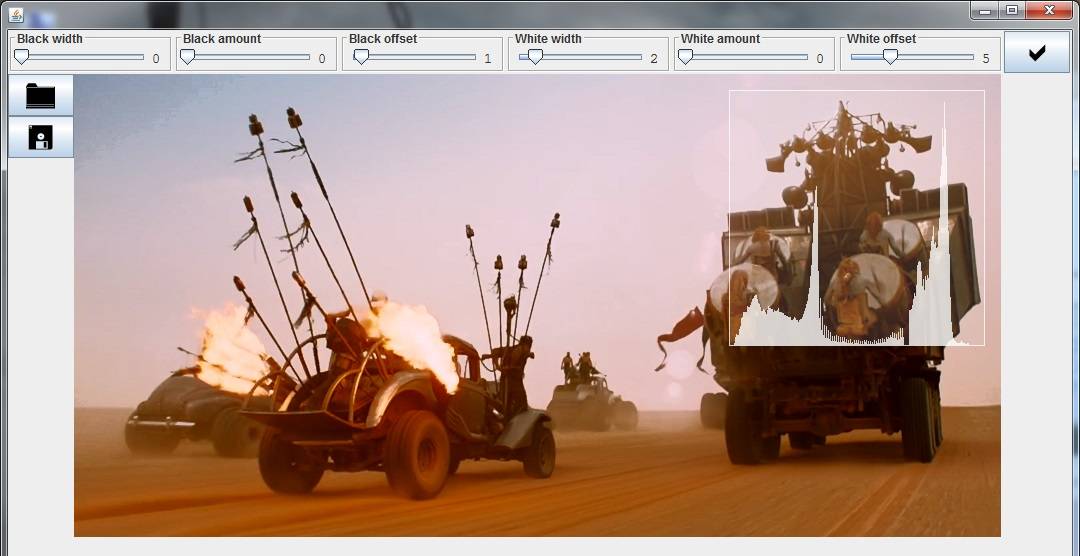
A rabbit hole of graphics and performance and primitives
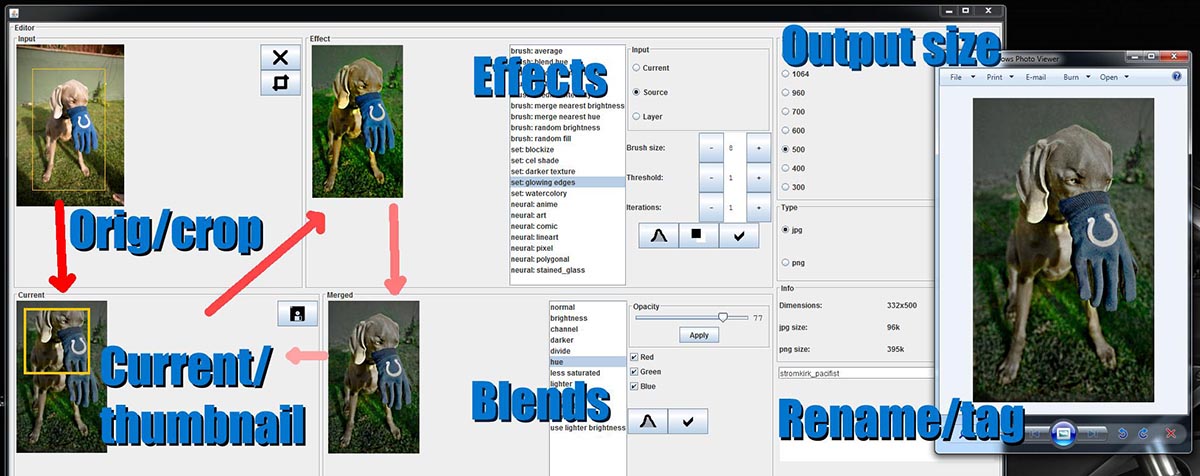
My graphics editor needed a second design pass. Even on my l33t gamer monitor,
a lot of downscaling is required to show four images on one screen with associated toolbars. What's more, I wanted to take a second hack at showing and correcting image histograms (see below).
My graphics code isn't very fast. It doesn't need to be and it's written in
Java so there's always going to be a generous performance ceiling. But for the histogram correction operation, I was seeing fifteen second run times to touch every pixel in a modest-size image (like 800x600).
Lessons previously learned
A long while ago I had the idea that I could make a more OO
BufferedImage by creating a 2d array of RGBPixel objects.
VoluminousUtilityClass.rgb2HSV(int argb) is nice, but pixel.hsv() is nicer. Alas there was an insurmountable performance hit from having millions of objects in lieu of millions of primitives. I ripped out the RGBPixel class from my BufferedImage 2.0, but kept it as a convenience type. Sometimes argb ints become RGBPixels for a series of operations before returning to their primitive roots.
Side note: I never liked the RGBPixel name (with potential peers HSVPixel, LuminancePixel, CIEPixel, etc.). It's effectively Color, but originally needed the semantics of being a datapoint in an image. The name stuck since I couldn't find anything better.
Signed bytes
So this histogram operation exposed performance issues in my graphics library and I intended to find them. With the RGBPixel lesson in mind, I immediately looked at my Byte object.
"Byte object? Whaaa?" Java uses signed bytes. It's not inherently terrible, but the lack of an unsigned alternative creates problems for graphics code that might, say, want to represent the value 200. You also can't "typedef short byte", though doing so would mean all of the client code should check bounds.
Being an OO/embedded/IDA guy, I created a proper Byte class. 0-255, no need to check if your int value is 256 because the type does that. A lot of the math that you have to do with A+R+G+B filed neatly under the Byte type, e.g.
public static Byte average(Collection<Byte> values).
Surely the use of Byte in many of my graphics operations (after they are unpacked from the argb int, for example) was the performance issue.
I should have never learned
I ripped out a lot of code, replacing all zillion Byte instances with short and the agonizing range checking code around it. But
nothing got noticeably faster. Here was the code:
canvas.parallelStream().forEach(
c -> adjustIntensity(canvas,
c,
black_threshold,
histogram.getMedian().getMin(),
white_threshold));
It, in parallel,
iterates over every pixel in the image and bumps the brightness based on the histogram bounds and median. Swapping the Bytes out for shorts didn't make any difference, what the heck?
histogram.getMedian().getMin(),
This was re-computing the image histogram in each call. My brain quietly expected the getMedian() return value to get put in a register and sent to each adjustIntensity() call since the getMedian() call was very thread-unsafe.
parallelStream() and exceptions
Java's parallelStream() is a really convenient way to do distributed processing since you can call it on any Collection but it doesn't natively handle exceptions.
The kinds of things you use parallel processing for are often complex enough to run into exceptional situations. Likewise, the kinds of things you use parallel processing for are often numerous enough that you don't want each thread to report the same issue n times.
Heretofore I was dumb and lazy and
implemented a bunch of "...Unchecked()" sister functions that caught the exception and, say, spit out a bright green pixel so I woudn't miss that there was an issue. It still meant exceptions disappeared, and the code became really cluttered. But it's easy to add another no-throw function and it's hard to do things the right way.
It really isn't hard to do things the right way. I saw some suggestions on StackOverflow, but decided to do this:
/**
* Provides an interface into parallel streams with exception handling.
* @param <T>
*
* Usage:
* Parallelizable<Type> lambda = t -> operation(t);
* Parallelizable.parallelize(collection_of_type, lambda);
*
*/
public interface Parallelizable<T> {
void run(T value) throws Exception;
/**
* Calls a parallel stream on the given collection. On throw,
* rethrows just the last exception.
* exception.
* @param <T>
* @param collection
* @param lambda
* @throws Exception
*
* Usage:
* Parallelizable<Type> lambda = t -> operation(t);
* Parallelizable.parallelize(collection_of_type, lambda);
*
*/
public static <T> void parallelize(final Collection<T> collection,
final Parallelizable<T> lambda)
throws Exception {
// The list is just a hack to have a final variable that I can
modify.
final List<Exception> list = new ArrayList<Exception>(1);
collection.parallelStream().forEach(t ->
{
try {
lambda.run(t);
}
catch (Exception e) {
list.clear();
list.add(e);
}
});
if (list.size() > 0) {
System.err.println("One or more of the parallel operations
failed, rethrowing last exception.");
throw list.get(0);
}
}
}
There are probably even more generic ways to do this but all of my use cases so far are on Lists or Sets. Why disappoint Future Chris by doing it 100% correct this time? This prints the last exception (and could be modified to aggregate a handful) and replaces the parallelStream().forEach() lines with two more succinct operations.
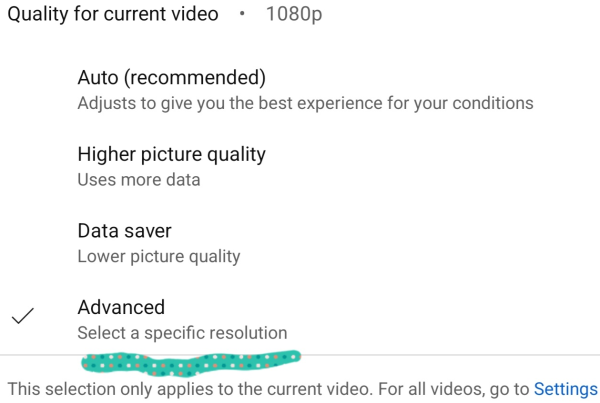
One final Google complaint
At what point did 1080 become an advanced setting?
Some posts from this site with similar content.
(and some select mainstream web). I haven't personally looked at them or checked them for quality, decency, or sanity. None of these links are promoted, sponsored, or affiliated with this site. For more information, see
.














![[+]](https://www.chrisritchie.org/kilroy/archive/2023/01/stellaris_event.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/07/warrior.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2023/01/_CRR2781.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2019/01/viscera_cleanup_mop.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2023/01/elon_birb.png){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/02/far_cry_view_00.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2023/01/_CRR2726.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2017/05/dying_light_stadium.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2023/01/tongue.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2016/04/division_helo_00.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2023/01/27_dresses.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2020/09/da_bears.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2023/01/_CRR2878.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/11/deezer.jpg){kind=link}