The first week of December almost always brings one of the biggest swells of the year. This one wasn't epic, but good enough to take a vacation Friday for some 0730 shooting and 0930 surfing. The lead image is a pretty good depiction of the difference between pre-sunrise shots and early-sunrise shots. The Black's cliffs make for a pretty tight window for good lighting.
All those dots in the lens photo aren't misleading, Black's was a zoo from road to path. This - combined with the crazy closeouts - made the photography actually quite difficult; it was hard to tell who would make the drop and the waves didn't hold shape for long.
I wanted to use Scripps Pier on an earlier shoot to get some background features. Turns out the field of view on the 500 is so tight I could get La Jolla as a backdrop if I shot down the line.
Neural style transfer
Last month I experimented some with the Tensorflow neural style transfer sample. Changes included tiling the content image and randomly sampling the style image(s).
I addressed the tile/seam issues by generating A/B outputs that have overlapped tiles that can be automatically or manually blended as a final step.
Compared to hard tile edges, even a straight overlay shows more style cohesion. With a little feathering, they stitch together nicely.
Last time I postulated that enough sampling would find an ideal tile from the style image. My implementation came up somewhat short as it didn't retain the last iteration's work - it would choose the best tile from a random sampling but then start over on the next full-image iteration. The previous work would be incorporated in the output, but the ideal(?) approach would be to continuously optimize the current best while still sampling other options.
Rather than track coordinates and loss, I decided to save off style squares containing the best style sample for a given content tile. Each pass of a given tile would start with the saved image and optimize it further, then see if other samples can achieve a lower loss value. Conceptually, this isn't too far off of standard error descent methods; I'm optimizing my best guess while checking random samples in case I'm not at the global minimum.
Cautious theta gang
I'm hesitant to write any puts that are longer than a week out. Still, 20k to make 200 in a week is better than a muni. It's a weird time:
Market at all time highs despite a major gdp reduction
Massive corona explosion
Vaccines arriving, but in small increments
Eviction moratoriums expiring this month
Unemployment and closing businesses happening/on the horizon
Stimulus maybe finally becoming a reality
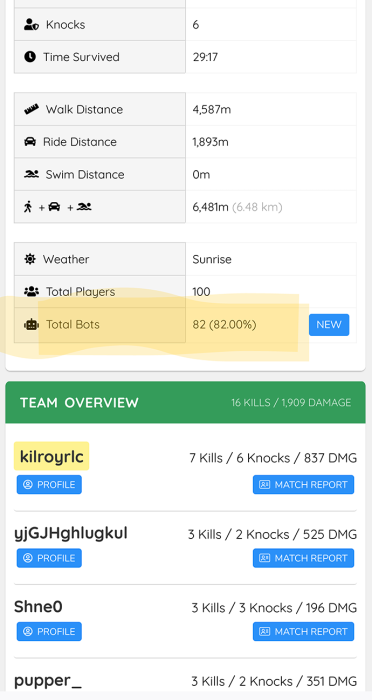
Bot league
Between being terrible, having a new squadmate, and low player counts, MMR has put us in bot league. At least the final circles have a few human players, but we've hit a bit of a goldilocks situation between unfairly hard and unfairly easy. Maybe that will change when the season rolls over.
Kshot linked a few cool things. There's a site to watch yourself get killed by streamers or, less frequently, enjoy their disgust when you knock them. And PUBG Lookup has a lot of cool match metrics, including show how many real players were fighting for that chicken dinner.
Jon put together quick clips of a physics corner case (that really isn't a corner case).
Cat eyes
Koko sent me a cat photo. I'm not sure if it was an iphone effect or her lights or her camera case, but it had a neat catch light effect.
Updated style transfer code
'''Neural style transfer with Keras. Modified as an experiment.
# References
- [A Neural Algorithm of Artistic Style](http://arxiv.org/abs/1508.
06576)
'''
from __future__ import print_function
from keras.preprocessing.image import load_img, save_img, img_to_array,
array_to_img
import numpy as np
from scipy.optimize import fmin_l_bfgs_b
import time
import random
import glob
import argparse
import os.path
from os import path
from keras.applications import vgg19
from keras import backend as K
def preprocess_image(img):
img = img_to_array(img)
img = np.expand_dims(img, axis=0)
img = vgg19.preprocess_input(img)
return img
def deprocess_image(x):
if K.image_data_format() == 'channels_first':
x = x.reshape((3, side_length, side_length))
x = x.transpose((1, 2, 0))
else:
x = x.reshape((side_length, side_length, 3))
# Remove zero-center by mean pixel
x[:, :, 0] += 103.939
x[:, :, 1] += 116.779
x[:, :, 2] += 123.68
# 'BGR'->'RGB'
x = x[:, :, ::-1]
x = np.clip(x, 0, 255).astype('uint8')
return x
def gram_matrix(x):
assert K.ndim(x) == 3
if K.image_data_format() == 'channels_first':
features = K.batch_flatten(x)
else:
features = K.batch_flatten(K.permute_dimensions(x, (2, 0, 1)))
gram = K.dot(features, K.transpose(features))
return gram
# the "style loss" is designed to maintain
# the style of the reference image in the generated image.
# It is based on the gram matrices (which capture style) of
# feature maps from the style reference image
# and from the generated image
def style_loss(style, combination):
assert K.ndim(style) == 3
assert K.ndim(combination) == 3
S = gram_matrix(style)
C = gram_matrix(combination)
channels = 3
size = side_length * side_length
return K.sum(K.square(S - C)) / (4.0 * (channels ** 2) * (size ** 2))
# an auxiliary loss function
# designed to maintain the "content" of the
# base image in the generated image
def content_loss(base, combination):
return K.sum(K.square(combination - base))
# edge detector - sum edges will be how busy it will look
def total_variation_loss(x):
assert K.ndim(x) == 4
if K.image_data_format() == 'channels_first':
a = K.square(
x[:, :, :side_length - 1, :side_length - 1] - x[:, :, 1:, :
side_length - 1])
b = K.square(
x[:, :, :side_length - 1, :side_length - 1] - x[:, :, :
side_length - 1, 1:])
else:
a = K.square(
x[:, :side_length - 1, :side_length - 1, :] - x[:, 1:, :
side_length - 1, :])
b = K.square(
x[:, :side_length - 1, :side_length - 1, :] - x[:, :
side_length - 1, 1:, :])
return K.sum(K.pow(a + b, 1.25))
def fidelity_loss(x, y):
assert K.ndim(x) == 3
assert K.ndim(y) == 3
if K.image_data_format() == 'channels_first':
x_g = K.sum(x[:3, :, :])
y_g = K.sum(y[:3, :, :])
return K.square(x_g - y_g)
else:
x_g = K.sum(x[:, :, :3])
y_g = K.sum(y[:, :, :3])
return K.square(x_g - y_g)
# Experiment with luminance
#if K.image_data_format() == 'channels_first':
# x_g = np.dot(x[0, :3, :, :], [0.2989, 0.5870, 0.1140])
# y_g = np.dot(y[0, :3, :, :], [0.2989, 0.5870, 0.1140])
# return K.square(x_g - y_g)
#else:
# x_g = np.dot(x[0, :, :, :3], [0.2989, 0.5870, 0.1140])
# y_g = np.dot(y[0, :, :, :3], [0.2989, 0.5870, 0.1140])
# return K.square(x_g - y_g)
# Returns style layers - this is the default (all), I experimented with
dropping random ones
def get_random_style_layers():
return ['block1_conv1', 'block2_conv1', 'block3_conv1', 'block4_conv1',
'block5_conv1']
def get_random_crop(image, width, height):
'''Returns a random subimage with the given width and height.'''
if (image is None or
width is None or width > image.width or
height is None or height > image.height):
raise
x_vals = image.width - width
y_vals = image.height - height
if (x_vals < 0 or y_vals < 0):
raise
# Crop to width and height, if specified.
x = 0
if (x_vals > 0):
x = int(random.randrange(x_vals))
y = 0
if (y_vals > 0):
y = int(random.randrange(y_vals))
print('Rand: ',str(x),', ',str(y),' from ',str(x_vals),' by ',
str(y_vals))
box = (x, y, x + width, y + width)
crop = image.crop(box)
return crop
def eval_loss_and_grads(x):
if K.image_data_format() == 'channels_first':
x = x.reshape((1, 3, side_length, side_length))
else:
x = x.reshape((1, side_length, side_length, 3))
outs = f_outputs([x])
loss_value = outs[0]
if len(outs[1:]) == 1:
grad_values = outs[1].flatten().astype('float64')
else:
grad_values = np.array(outs[1:]).flatten().astype('float64')
return loss_value, grad_values
def random_style_tile():
image = style_images[random.randrange(len(style_images))]
return get_random_crop(image, side_length, side_length)
class Evaluator(object):
def __init__(self):
self.loss_value = None
self.grads_values = None
def loss(self, x):
assert self.loss_value is None
loss_value, grad_values = eval_loss_and_grads(x)
self.loss_value = loss_value
self.grad_values = grad_values
return self.loss_value
def grads(self, x):
assert self.loss_value is not None
grad_values = np.copy(self.grad_values)
self.loss_value = None
self.grad_values = None
return grad_values
side_length = 224 # VGG19 is 224x224x3
step = 168
# Iteration hyperparameters (modify these)
iterations_per_image = 32 # Number of image traversals
samples_per_tile = 5 # Number of style tiles to try per iteration
iterations_per_sample = 16 # Number of style transfer iterations per
sample
# Use all png files from the style subdirectory, random 224 squares will
be used
# from these files to perform style transfer - so image size should be
# approximately the dimensions of the content.
style_files = glob.glob('style/*.png')
file_id = random.randrange(696969)
# Load content.png, the size of this image will significantly impact run
time.
content_image = load_img('content.png')
content_width, content_height = content_image.size
# Load style images.
style_images = []
for style_name in style_files:
style_image = load_img(style_name)
style_images.append(style_image)
# If this setup was run previously, use the existing output image.
if (os.path.isfile('last.png')):
output_image_a = load_img('last_a.png')
output_image_b = load_img('last_b.png')
else:
output_image_a = load_img('content.png')
output_image_b = load_img('content.png')
# Compute the tile count/step size. There will be overlap and it should
# be a good thing.
x_tiles = int(content_width / step)
y_tiles = int(content_height / step)
# Add iterleaved tiles
tiles = []
x_start = 0
for i in range(x_tiles):
y_start = 0
for j in range(y_tiles):
if (i + j) % 2 == 0:
tiles += [(x_start, y_start, True)]
else:
tiles += [(x_start, y_start, False)]
y_start = y_start + step
x_start = x_start + step
feature_layers = get_random_style_layers()
print('Style layers: ' + str(feature_layers))
total_variation_weight = random.uniform(0.001, 0.1)
style_weight = random.uniform(0.001, 0.1)
content_weight = random.uniform(0.0001, 0.1)
fidelity_weight = random.uniform(0.001, 0.1)
# Number of times to cover the entire image (optimize each tile)
for image_iteration in range(iterations_per_image):
print('Iteration: ', image_iteration)
# Randomize hyperparameters because I don't know what good values are.
# Modify these/make them fixed.
fidelity_weight *= 2
content_weight *= 2
# Bump the tile a random value to do a smoother stitch.
fname_a = 'output_' + str(file_id) + '_%d_a.png' % image_iteration
fname_b = 'output_' + str(file_id) + '_%d_b.png' % image_iteration
# Iterate over each image tile.
for tile in tiles:
x_start = tile[0]
y_start = tile[1]
is_a = tile[2]
print(' Processing tile: (', x_start, ', ', y_start, ')')
style_file = 'style_' + str(x_start) + '_' + str(y_start) + '.png'
box = (x_start, y_start, x_start + side_length, y_start +
side_length)
tile_content = content_image.crop(box)
base_image = K.variable(preprocess_image(tile_content))
best_loss = -1
# For each tile, sample the random portions of the style image(s)
and choose
# the best of the lot.
for sample_index in range(samples_per_tile):
# Set baseline error with current best style sample
if (sample_index == 0 and os.path.isfile(style_file)):
print(' Using existing style: ',style_file)
tile_style = load_img(style_file)
using_best = True
else:
print(' Using random tile')
tile_style = random_style_tile()
using_best = False
evaluator = Evaluator()
if (is_a):
tile_output = output_image_a.crop(box)
else:
tile_output = output_image_b.crop(box)
x = preprocess_image(tile_output)
style_reference_image = K.variable(preprocess_image(tile_style)
)
if K.image_data_format() == 'channels_first':
combination_image = K.placeholder((1, 3, side_length,
side_length))
else:
combination_image = K.placeholder((1, side_length,
side_length, 3))
# combine the 3 images into a single Keras tensor
input_tensor = K.concatenate([base_image,
style_reference_image,
combination_image], axis=0)
# Reinitialize VGG19. There's probably a way to do this once
and
# improve performance.
model = vgg19.VGG19(input_tensor=input_tensor, weights=
'imagenet', include_top=False)
outputs_dict = dict([(layer.name, layer.output) for layer in
model.layers])
# combine these loss functions into a single scalar
loss = K.variable(0.0)
layer_features = outputs_dict['block5_conv2']
base_image_features = layer_features[0, :, :, :]
combination_features = layer_features[2, :, :, :]
loss = loss + content_weight *
content_loss(base_image_features, combination_features)
for layer_name in feature_layers:
layer_features = outputs_dict[layer_name]
style_reference_features = layer_features[1, :, :, :]
combination_features = layer_features[2, :, :, :]
loss = loss + (style_weight / len(feature_layers)) *
style_loss(style_reference_features, combination_features)
loss = loss + total_variation_weight *
total_variation_loss(combination_image)
loss = loss + fidelity_weight *
fidelity_loss(combination_features, base_image_features)
# get the gradients of the generated image wrt the loss
grads = K.gradients(loss, combination_image)
outputs = [loss]
if isinstance(grads, (list, tuple)):
outputs += grads
else:
outputs.append(grads)
f_outputs = K.function([combination_image], outputs)
# Use optimization iterations hyperparameter, for the current
best,
# just do half as many.
iterations = iterations_per_sample
if (using_best == True):
iterations = int(iterations / 2)
# With this content/style combo, use the style transfer
algorithm.
for iteration in range(iterations):
x, min_val, info = fmin_l_bfgs_b(evaluator.loss, x.
flatten(),
fprime=evaluator.grads,
maxfun=20)
if (min_val > 1000000):
min_str = str(int(min_val / 1000000)) + 'M'
elif (min_val > 1000):
min_str = str(int(min_val / 1000)) + 'k'
else:
min_str = str(int(min_val))
print(' Loss[', iteration, ']: ', min_str)
# If this is the first style sample or it's better than the
last
# use this output.
if (best_loss == -1 or min_val < best_loss):
print(' Updating from prev: ', min_val / 1000000, 'M
< ', best_loss / 1000000, 'M')
img = array_to_img(deprocess_image(x.copy()))
best_loss = min_val
if (is_a):
output_image_a.paste(img, (x_start, y_start))
else:
output_image_b.paste(img, (x_start, y_start))
save_img(style_file, tile_style)
print(' Updated style file: ', style_file)
else:
print(' Skipping update: ', min_val / 1000000, 'M > ',
best_loss / 1000000, 'M')
# Reset the back end
K.clear_session()
# Save per-tile progress for long runs
if (samples_per_tile * iterations_per_sample > 64):
save_img(fname_a, output_image_a)
save_img(fname_b, output_image_b)
save_img('last_a.png', output_image_a)
save_img('last_b.png', output_image_b)
save_img(fname_a, output_image_a)
save_img(fname_b, output_image_b)
save_img('last_a.png', output_image_a)
save_img('last_b.png', output_image_b)
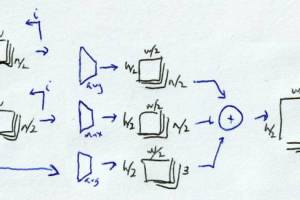
After some interesting reads, I implemented a convolution+pooling block inspired by ResNet. It looks like this:
Related / external
Risky click advisory: these links are produced algorithmically from a crawl of the subsurface web (and some select mainstream web). I haven't personally looked at them or checked them for quality, decency, or sanity. None of these links are promoted, sponsored, or affiliated with this site. For more information, see this post.
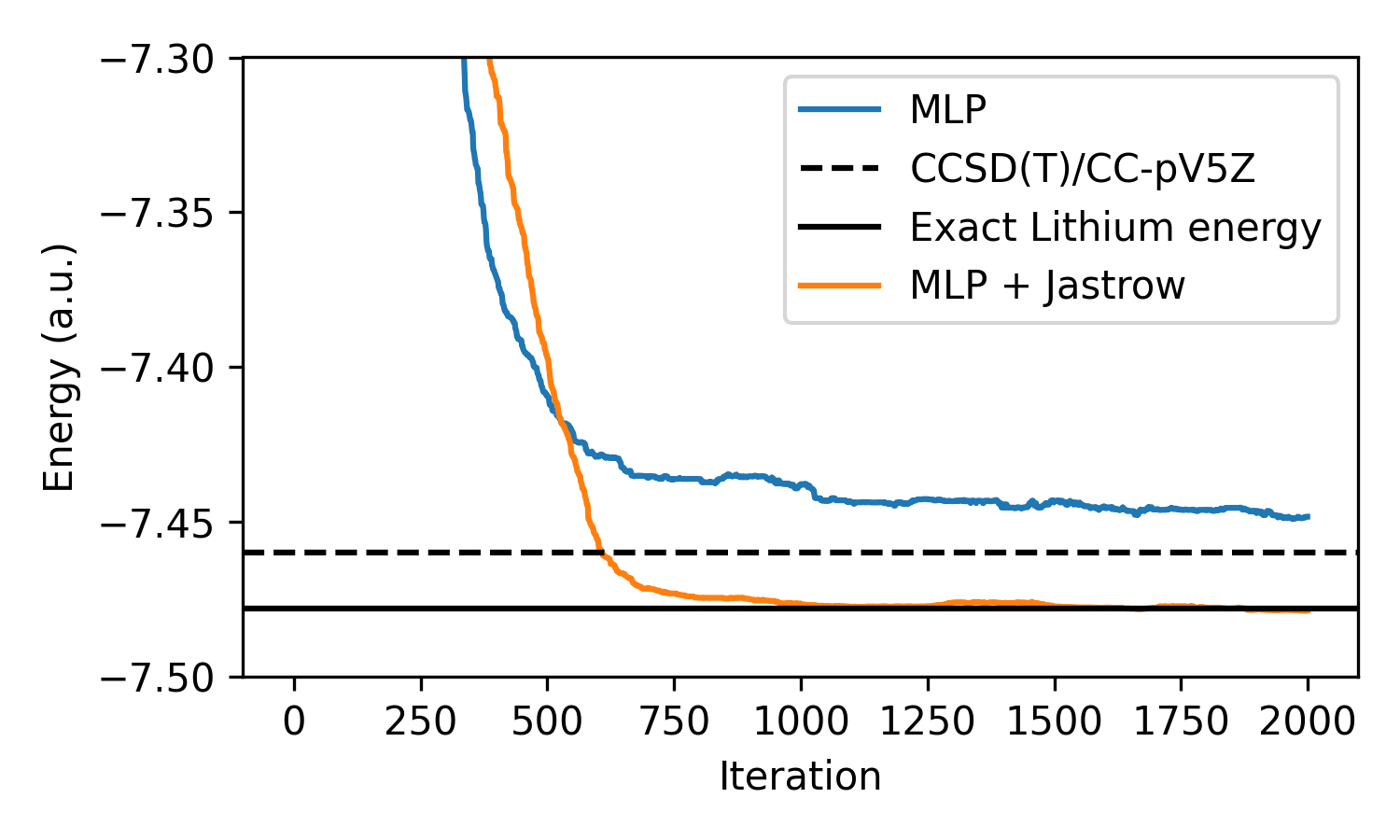
One interesting application area of AI in the sciences is quantum chemistry. At the center of quantum chemistry lies the Schrödinger equation. This equation can be solved ab initio, meaning purely from first principles without any experimental data or external knowledge. Accurate solutions to the Schrödinger equation are essential for determining the electronic structure of molecules or materials, which in turn can be used to derive physical and chemical properties. Therefore, the abi...
By the end of this blog post, we aim to improve the results of my previous blog post of approximating circular bokeh with a sum of 4 separable filters and reducing its artifacts (left) through an offline optimization process to get the results on the right. In today's blog post I will look at two...
In this tutorial, we will learn two different methods to implement neural networks from scratch using Python: Extremely simple method: Finite difference Still a very simple method: Backpropagation
































![[+]](https://www.chrisritchie.org/kilroy/archive/2020/09/da_bears.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/07/warrior.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2020/10/cash_secured_putt.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/02/far_cry_view_00.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2020/09/draft.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2016/04/division_helo_00.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2020/09/virus.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2017/05/dying_light_stadium.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2020/11/silverado.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/11/deezer.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2020/11/rig.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2016/08/witches_lair.jpg){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2020/11/the_celt.png){kind=link}
![[+]](https://www.chrisritchie.org/kilroy/archive/2015/02/far_cry_items.jpg){kind=link}